论文推荐

赛尔原创@COLING24 |即插即用!自动提取领域相关特征提升泛化能力
现有的跨域文本分类方法往往忽视了领域感知特征的重要性,只关注提取领域不变特征或任务无关特征。我们提出的自监督蒸馏方法通过在目标域中利用未标记数据来捕获领域感知特征,从而提高模型在目标域上的性能。
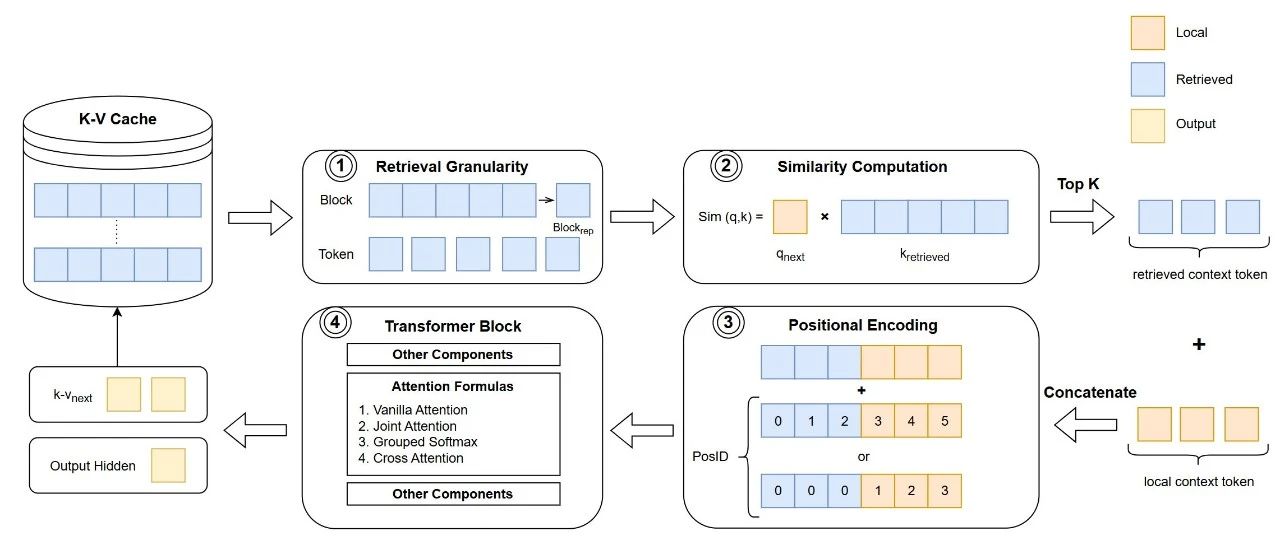
赛尔原创@COLING24 |无需标注即可增强模型 COT 能力
在使用包含推理步骤的数据进行训练后,模型能够获得更强的推理能力。然而, 由于高标注成本, 拥有高质量推理步骤的数据集相对稀缺。为解决这个问题, 我们提出了自我激励学习框架来增强LLM的推理能力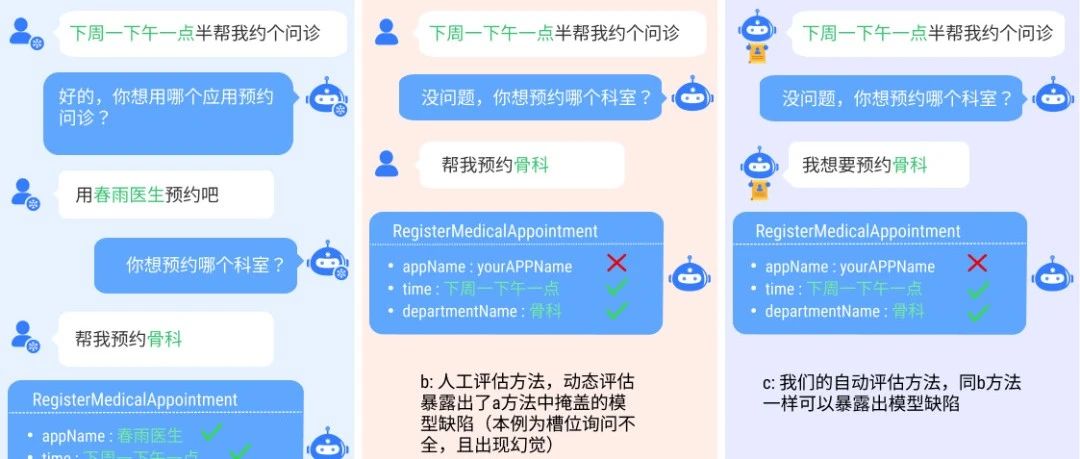
赛尔原创@COLING2024 | 人工智能助手API调用能力的动态评估方法
论文名称:Beyond Static Evaluation: A Dynamic Approach to Assessing AI Assistants’ API Invocation Capabilities 论文作者:牟虹霖,徐阳,冯云...
赛尔原创@COLING2024 | 面向编程的自然语言处理综述
本文围绕编程语言的两大核心特点:结构性和功能性,系统梳理了将自然语言处理技术应用于编程领域的研究进展,内容涵盖任务定义、数据集构建、评估方法、关键技术以及代表性模型等诸多方面,以期为读者全面展现这一新兴交叉领域的研究现状。
赛尔原创@COLING2024 | LM-Combiner:通过模型改写实现更精准的语法纠错
语法纠错旨在识别并纠正文本中的常见语法错误。前人方法需要较多的计算资源并且损失了一部分召回率。本文通过改写单一校对系统的输出来过滤其中的过度纠正现象;同时由于经过针对性训练,对过度校对错误判断更准确,能够保证改写后的输出错误召回率保持不变。
今日arXiv最热NLP大模型论文:做到头了!清华和哈工大把大模型量化做到了1比特
清华和哈工大提出了一个名为OneBit的1位量化感知训练框架把大模型量化做到了1比特,同时保证了时间和空间效率以及模型性能之间的平衡,至少能达到非量化性能的83%,而且训练过程还特别稳定。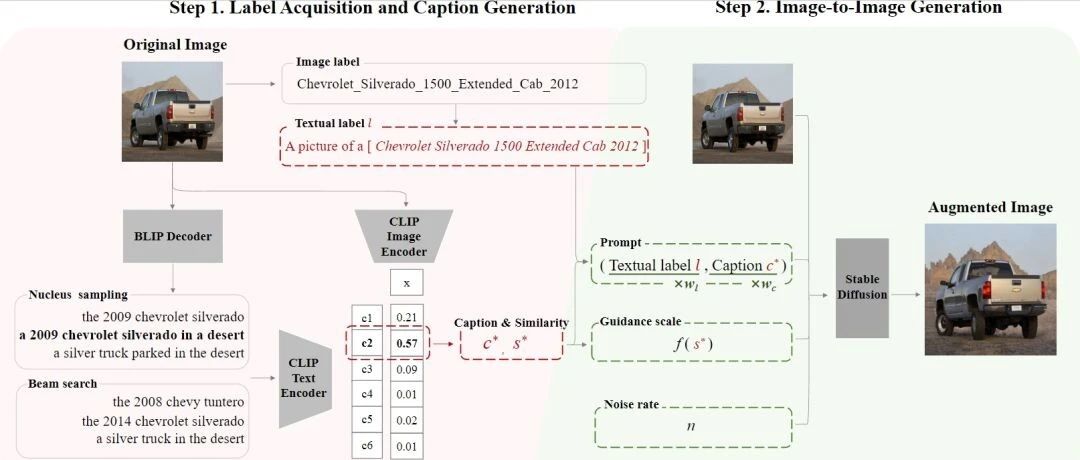
赛尔原创@AAAI 2024 |语义引导的生成式图像增广方法
本文提出SGID,一种语义引导的生成式图像增广方法,用于在图像分类的数据增广中平衡增广图像的多样性和语义一致性,克服了以往的扰动式方法及生成式方法的局限。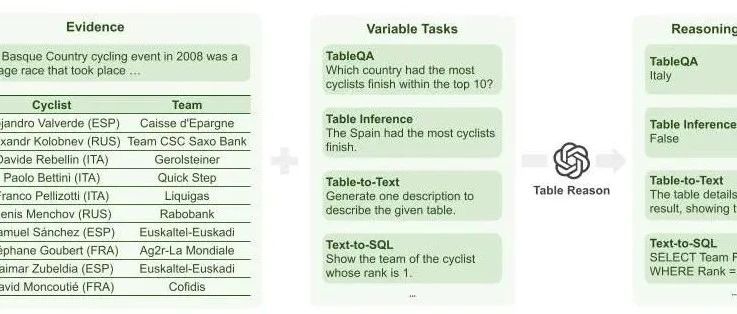
赛尔笔记 | 面向表格数据的大模型推理综述
我们在本文对现有的基于LLM的表格推理相关工作进行梳理,来促进该领域上的研究。我们介绍表格推理任务的定义与主流数据集;我们给出基于LLM的表格推理方法的分类,并总结了该任务现有的研究工作;我们给出各个研究方向的可能改进,启发未来的研究思路。
赛尔原创@EMNLP 2023 | 通过跨语言提示改进零样本 CoT 推理能力
本文引入了简单有效的CLP帮助思维链范式在不同语言间进行有效地对齐,并进一步提出了CLSP,利用不同语言专家的知识和不同语言间更加多样的思考方式,集成了多个推理路径,显著地提高了self-consistency的跨语言性能。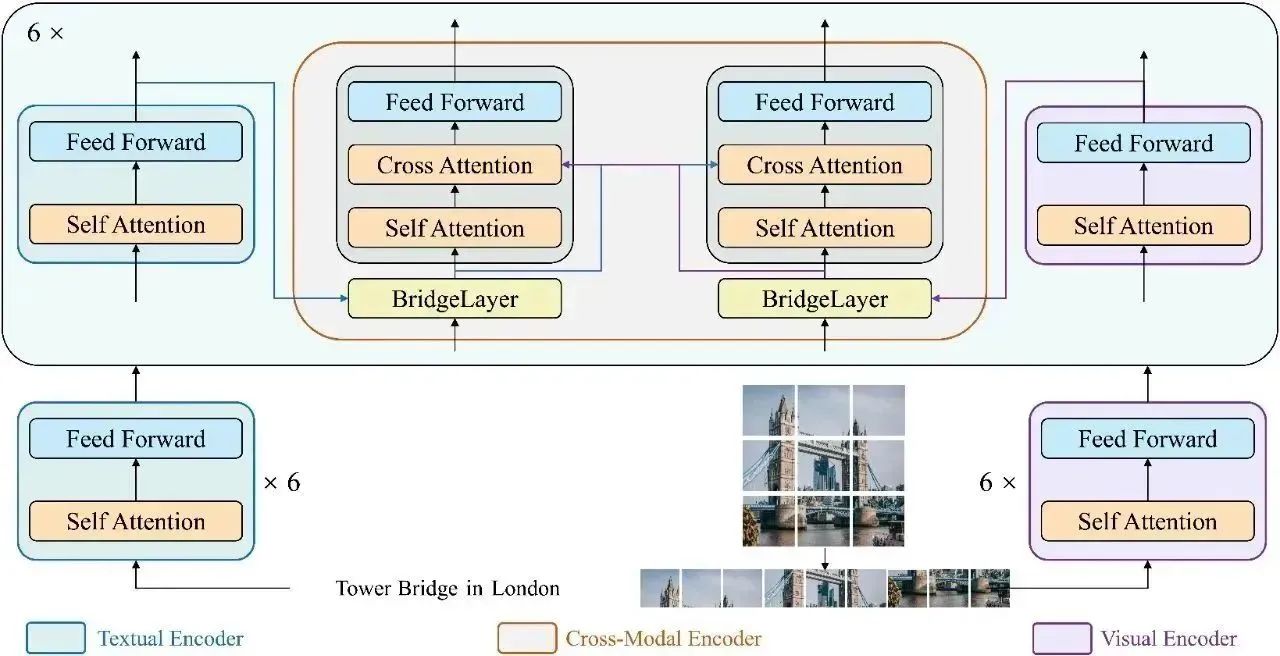
赛尔原创@AAAI 2023 | BridgeTower- 在视觉语言表示学习中建立编码器间的桥梁
在本文中,我们提出了BridgeTower,它引入了多个BridgeLayer,在单模态编码器的顶层和跨模态编码器的每一层之间建立连接。这使得预训练单模态编码器中的不同语义层次的视觉和文本表示,通过BridgeLayer与跨模态表示进行融合,从而促进了跨模态编码器中,高效的,自下而上的跨模态对齐与融合。仅使用400万张图像进行视觉语言预训练,BridgeTower在各种下游的视觉-语言任务中取得了非常强大的性能。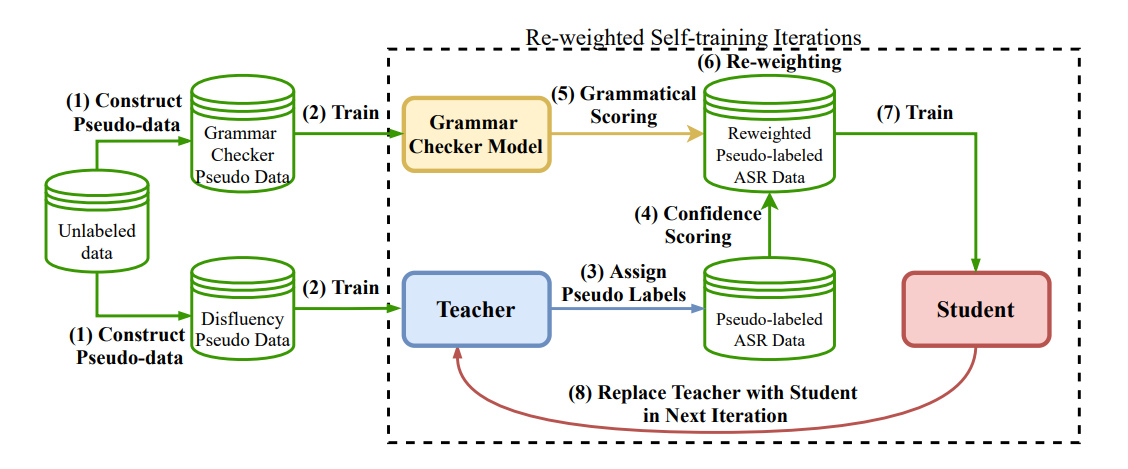
赛尔原创@COLING 2022 | 融合自适应机制与自训练框架的无监督文本顺滑方法
在这项工作中,我们提出了一种基于Re-weighting的自适应无监督训练框架来更好的解决文本顺滑任务。我们通过引入词级别置信与句子级别判别信息来赋予每个样本不同权重进行学习,同时采用更高效的基于对比的句对语法判别器,实现了一个更鲁棒、性能更好的无监督文本顺滑系统。实验表明,我们的优化方案能有效缓解选择偏差和错误累计的问题,在SWBD以及多个跨领域数据集上均有所提升。
赛尔原创@COLING 2022 | MetaPrompting:基于元学习的soft prompt初始化方法
本文提出了MetaPrompting,将基于优化的元学习方法推广到soft prompt模型中,来处理少标注文本任务。MetaPrompting利用源领域数据进行元学习,搜索能够更快、更好地适应于新的少标注人物的模型参数初始化点。在4个少标注文本分类数据集上的实验结果表明,MetaPrompting相比于朴素的soft prompt模型以及其他基于元学习的基线模型取得了更好的效果,达到了新的SOTA性能。
赛尔原创@COLING 2022 | CCTC:面向中文母语使用者的跨句子文本纠错数据集
中文文本纠错(Chinese Text Correction, CTC)主要针对中文拼写错误和语法错误进行检测和纠正。目前大部分中文拼写纠错和语法纠错的测试集都是单句级别的,并且是由外国的汉语学习者撰写的。我们发现中文母语使用者犯的错误和非母语使用者犯的错误有很大的不同,直接使用目前已有的一些数据集作为测试集来为面向中文母语使用者准备的校对系统进行评测并不合适。此外,一些错误通常还需要上下文信息来进行检测和纠正。在本文中,我们提出了一个基于中文母语使用者撰写文本的跨句子中文文本纠错测试集CCTC。
ACL@2022 | 反向预测更好?基于反向提示的小样本槽位标注方法
本文录用于ACL 2022 Findings。提示学习方法在如槽位标注等词级别任务上十分低效。本文探索了一种反向提示方法,并提出了迭代预测策略来建模标签之间的依赖关系。我们的方法在多个数据集上均有提升,并大幅加快了槽位标注的预测速度。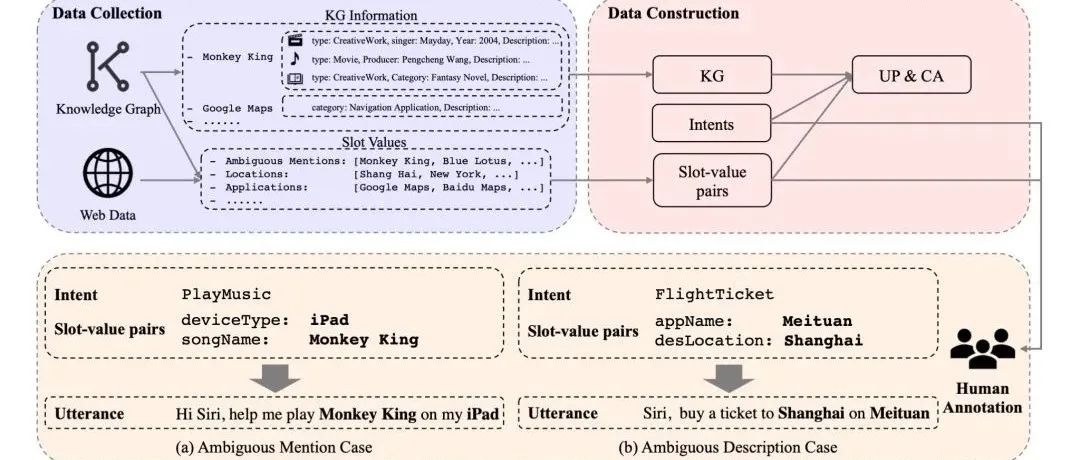
赛尔原创@AAAI 2022|基于Profile信息的口语语言理解基准
本文录用于AAAI 2022。本文研究基于Profile的口语语言理解任务。本文标注了约含五千条数据的中文数据集,并使用多层次知识适配器来有效引入辅助Profile信息,实验表明,该方式能够有效提升SLU模型在ProSLU任务上的表现。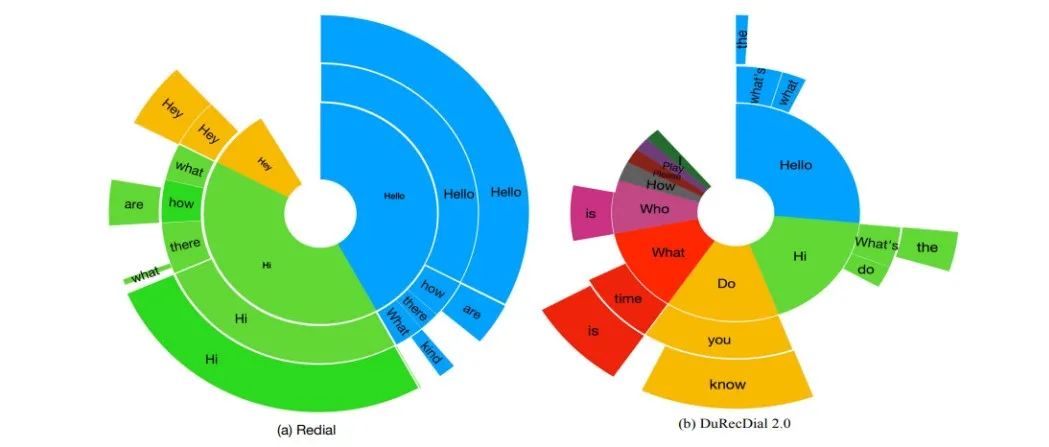
赛尔原创@EMNLP 2021 | 多语言和跨语言对话推荐
本文录用于EMNLP 2021。为促进多语言和跨语言对话推荐的研究,我们构建了第一个中英双语并行对话推荐数据集DuRecDial 2.0,并定义了5个任务。自动评估和人工评估结果表明,使用英文对话推荐数据可以提高中文对话推荐的性能。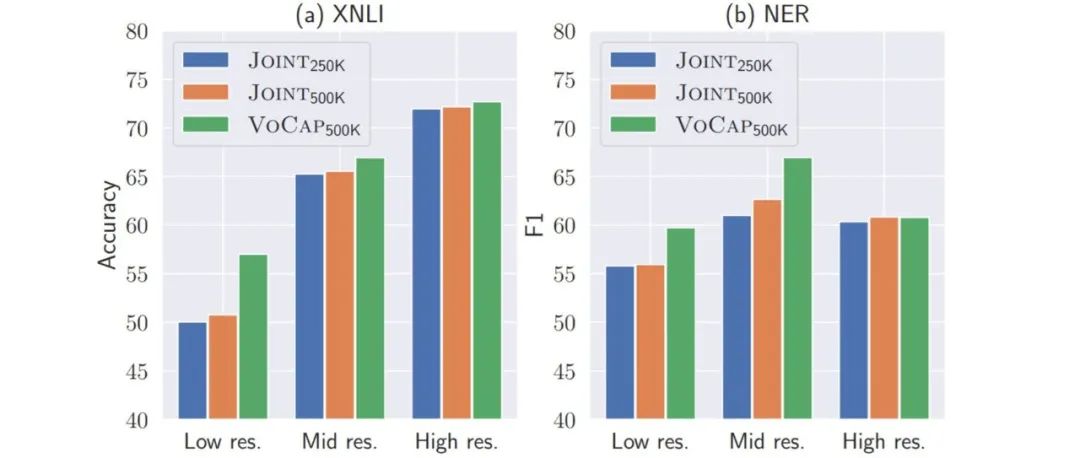
赛尔原创@EMNLP 2021 | 预训练跨语言模型中的大词表构建及使用
本文录用于EMNLP 2021。本文首先提出VoCap词表构建算法以构建更大的多语言词表,综合考虑每种语言的语言特定词汇能力及预训练语料大小为每种语言分配合适的词表大小。实验结果表明,基于VoCap方法构建的多语言词表要优于之前的方法。
赛尔原创@ACL Findings | 任务共舞,小样本场景下的多任务联合学习方法初探
本文录用于Findings of ACL 2021。现有Few-shot模型通常一次只学习一个单一任务,如何在少样本情景下联合学习多个任务的方法还少有研究。本文针对这一问题提出了“共舞”(ConProm)模型,大幅提升了联合准确率。
赛尔原创 | 首个任务型对话系统中生成模块资源库Awesome-TOD-NLG-Survey开源!
我们整理开源了一个仓库,详细、全面地总结了 NLG 领域发展过程中的工作,包括方法分类和相关的开源资源,并且涵盖了一些前沿方向的讨论。我们希望该工作能够对促进该领域发展贡献力量,也相信该资源库值得对 NLG 领域感兴趣的同学们了解和关注。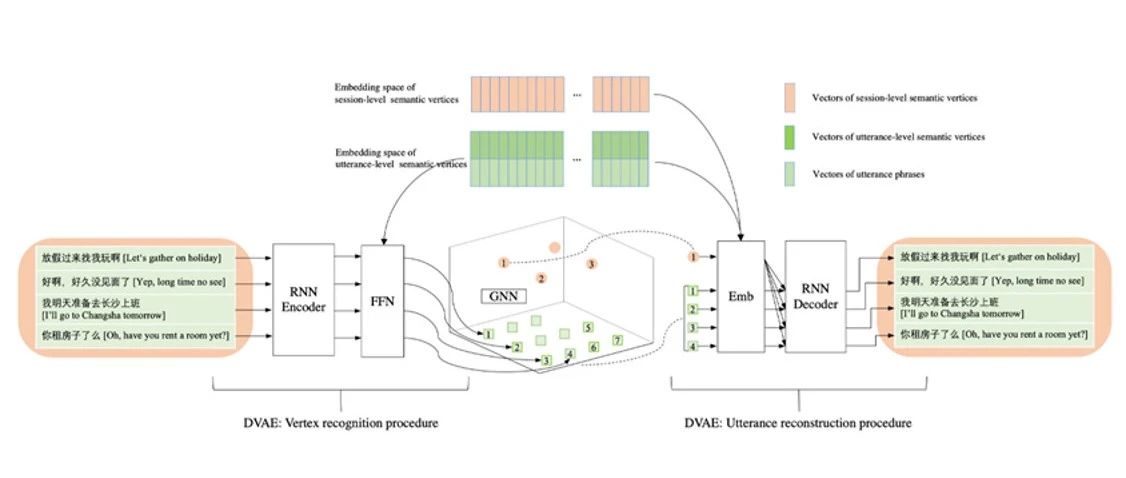
赛尔原创@ACL 2021 | 开放域对话结构发现
本文录用于ACL 2021。本文设计了一种自监督的对话结构发现模型。实验结果表明,自监督的DVAE-GNN模型能发现有意义的层次化对话结构,且对话结构图对于提升多轮对话连贯性等有重要作用。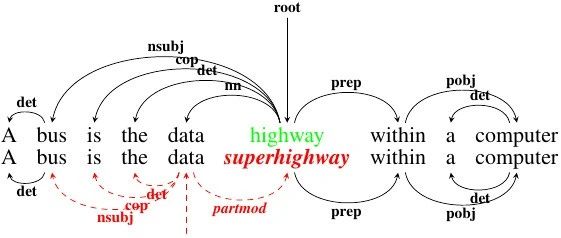
赛尔原创@ACL Findings | 基于高质量对抗样本的依存分析器鲁棒性探究
现有的针对依存分析任务的对抗攻击基本都集中于攻击方法本身,而忽略了较低的对抗样本质量。为了解决该问题,我们提出了一种方法,使用更多生成方法和更严格的过滤器来生成高质量的对抗样本,并使用对抗学习和模型融合方法有效提高了分析器的鲁棒性。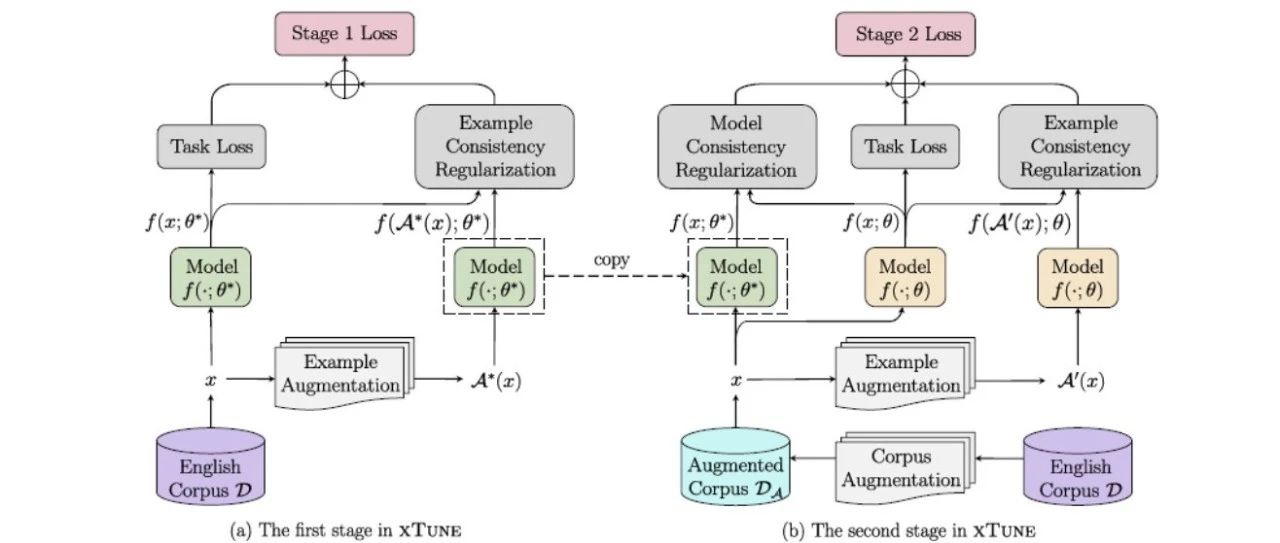
赛尔原创@ACL 2021 | 基于一致性正则的跨语言微调方法
本文录用于ACL 2021。跨语言微调指通过在源语言标注数据微调跨语言模型,使得任务的监督信息能够迁移到其他目标语言。本文提出了xTune方法,通过两种一致性正则来更好地利用跨语言增广数据,从而提升多种下游任务中跨语言微调的性能。
赛尔原创 | N-LTP:基于预训练模型的中文自然语言处理平台
自然语言处理(NLP)工具包种类繁多 ,但用于中文NLP任务的高性能和高效率工具包相对较少。为此我们推出了用于中文NLP任务的神经自然语言处理工具包LTP,支持六大NLP任务,在效率和性能上都取得了不错的效果。
赛尔原创 | 车万翔教授团队最新综述:对话系统中口语语言理解研究的新进展与新领域
在本文中,我们整理了近十年来SLU领域的相关进展,内容主要包含三个方面:(1)最近SLU领域进展的全面总结;(2)复杂情景下研究的挑战和机遇;(3)SLU全面的代码,数据集等资源。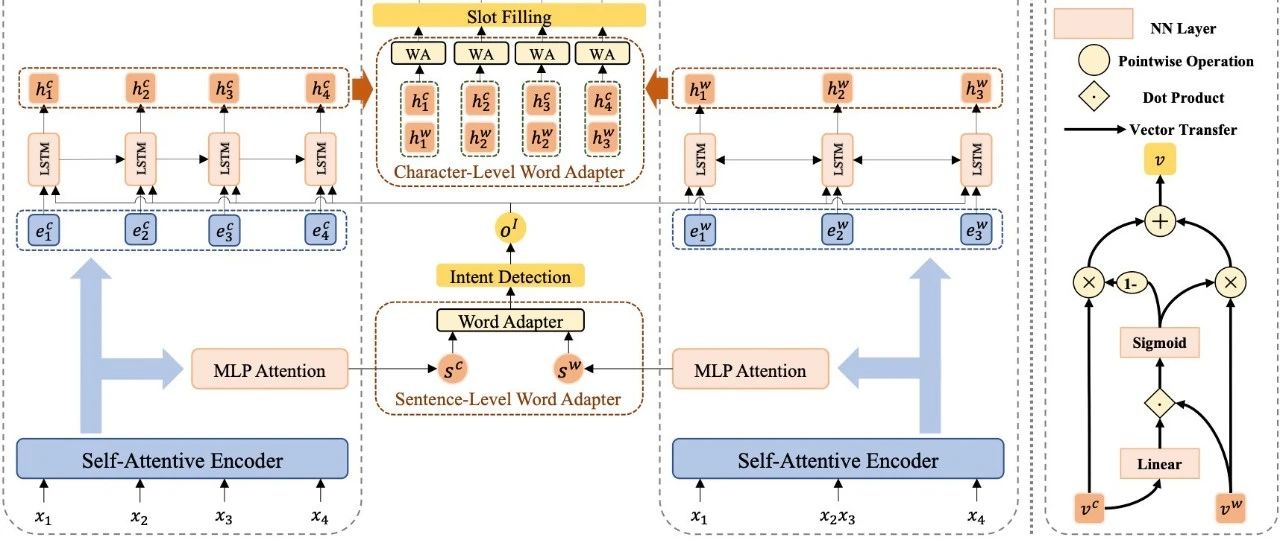
赛尔原创@ICASSP 2021 | 首次探索中文词信息增强中文口语语言理解!
本文录用于ICASSP 2021,在本文中作者提出了一个多层次的单词适配器,首次向中文口语语言理解中引入中文单词信息,实现了不同级别任务的词信息表示定制化。在两个公开的中文数据集上进行的实验表明,模型达到了当前最佳的性能。
赛尔笔记 | 新分类!全总结!最新Awesome-SLU-Survey资源库开源!
本文主要介绍我们所整理的一个仓库,包含了SLU领域最新工作的总结,还涵盖了一些前沿方向的讨论,并且也包括了一些开源资源总结,希望能对这个领域的发展有一点帮助,值得对SLU感兴趣的同学了解、关注。
赛尔原创@AAAI 2021 | 纠结于联合学习中的建模方法?快来看看图网络显式建模!
本文录用于AAAI 2021。在本文中,作者提出了一个协同交互的图注意力网络,首次尝试同时结合上下文信息和相互交互信息来进行联合对话行为识别和情感分类。作者在两个公开数据集上进了实验,结果表明该模型获得了最佳的性能。
赛尔原创@AAAI 2021 | 数据增强没效果?试试用Cluster-to-Cluster生成更多样化的新数据吧
本文录用于AAAI 2021。我们提出了一种全新的多到多生成模型C2C-GenDA来实现数据增强。在数据不足的情景下,这种新的生成范式在两个公开数据集上分别带来了7.99 (11.9%↑) 和5.76 (13.6%↑) F1的提升。
赛尔原创@AAAI2021 | 小样本学习下的多标签分类问题初探
本文录用与AAAi 2021。小样本学习(Few-shot Learning)近年来吸引了大量的关注,但是针对多标签问题(Multi-label)的研究还相对较少。在本文中,我们以用户意图检测任务为切入口,研究了的小样本多标签分类问题。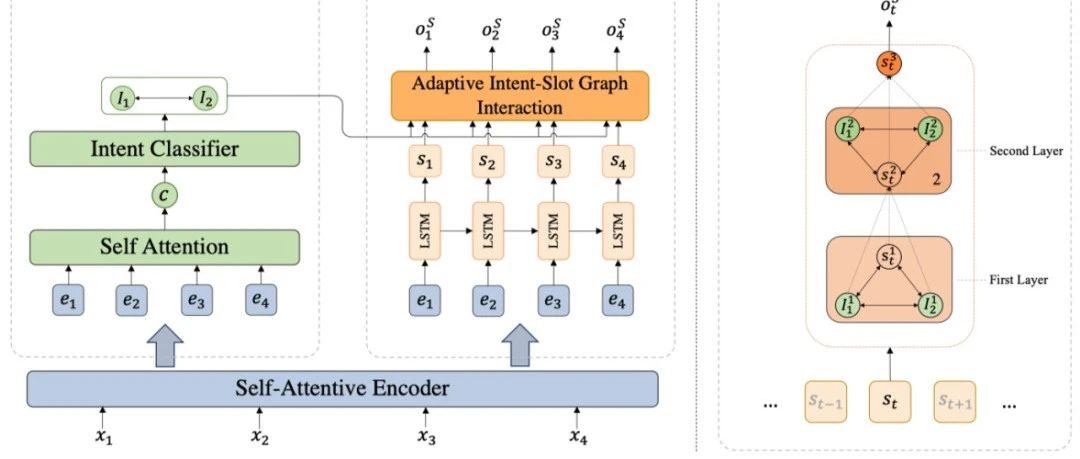
赛尔原创@Findings | 基于动态图交互网络的多意图口语语言理解框架
本文录用于Findings of EMNLP2020, 针对多意图SLU任务,提出一种自适应图交互网络来自动捕获相关意图信息来进行每个单词的槽位填充。该模型在三个数据集上达到SOTA,在单意图数据集上超过前人模型,进一步验证模型的有效性。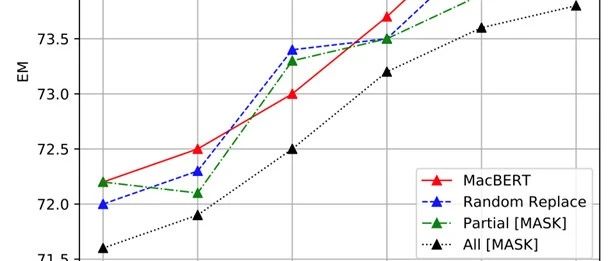
赛尔原创@Findings | 中文预训练语言模型回顾
本文录用于Findings of EMNLP 2020。本文将主流预训练模型应用于中文场景并进行深度对比,并提出了基于文本纠错的预训练语言模型MacBERT,解决了预训练模型中“预训练-精调”不一致的问题,在多个中文任务上获得显著性能提升。
赛尔原创@EMNLP 2020 | 且回忆且学习:在更少的遗忘下精调深层预训练语言模型
本文录用于EMNLP 2020。本文提出且回忆且学习的机制,通过采用多任务学习同时学习预训练任\x0a务和目标任务,提出了预训练模拟机制和迁移机制。实验表明文章提出的方法在GLUE上达到了最优性能。
赛尔原创|EMNLP 2020 融合自训练和自监督方法的无监督文本顺滑研究
本文录用于EMNLP 2020。在自然语言处理中,顺滑任务的目是识别出话语中自带的不流畅现象。本文融合了自训练和自监督两种学习方法,探索无监督的文本顺滑方法。实验结果表明,本方法在不使用有标注数据进行训练的情况下,取得了非常不错的性能。
赛尔原创 | ACL20 让模型“事半功倍”,探究少样本序列标注方法
少样本学习是近年来的热点,但是针对对话等NLP具体问题的研究仍然方兴未艾。本文从对话语义槽标记问题入手,首次研究了少样本序列标注问题。我们提出坍缩依赖迁移机制和L-TapNet模型,取得了14.64 F1的大幅提升。
赛尔原创 | ACL20 用于多领域端到端任务型对话系统的动态融合网络
本文录用于ACL2020。本文首次将 shared-private 应用在了多领域端到端对话任务中,并成功将表示用于query知识库提高性能,还提出了动态融合网络,有效地捕捉了领域间更细粒度的相关性,在低资源情况下也取得了很好的效果。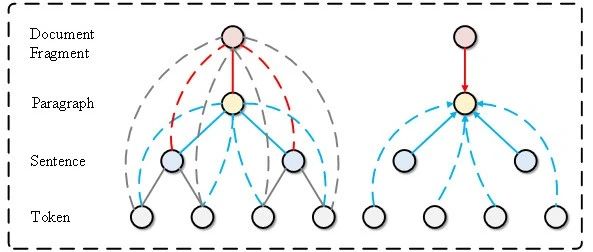
赛尔原创 | ACL20 基于图注意力网络的多粒度机器阅读理解文档建模
本文录用于ACL2020。在本文中,针对NQ数据集的两个粒度答案的特点,我们提出了基于BERT和图注意力网络的多粒度机器阅读理解框架,通过联合训练考虑NQ两个粒度答案之间的依赖关系,并且在NQ数据集上验证了方法的有效性。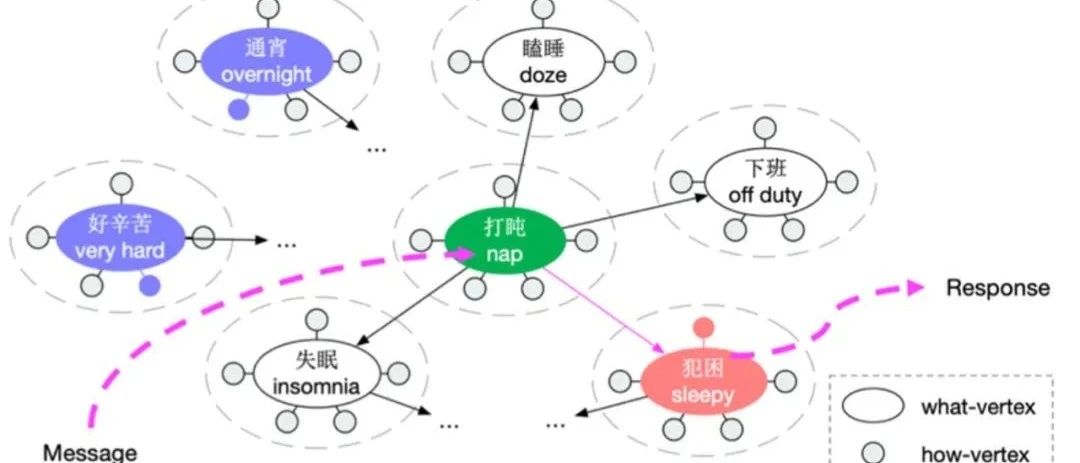
赛尔原创 | ACL20 基于对话图谱的开放域多轮对话策略学习
本文录用于ACL2020。本文提出用图的形式捕捉对话转移规律作为先验信息,用于辅助开放域多轮对话策略学习,还提出了一个基于对话图的策略学习框架来指导回复生成。的开放域多轮对话规划.jpg)
赛尔原创 | AAAI20 基于Goal(话题)的开放域多轮对话规划
本文录用于AAAI2020,提出了一种基于话题的开放域多轮对话规划方法,并将该任务分为两个子任务:话题和深入话题聊天。该模型在用户兴趣一致性、对话一致性和知识准确性方面优于最新的基线。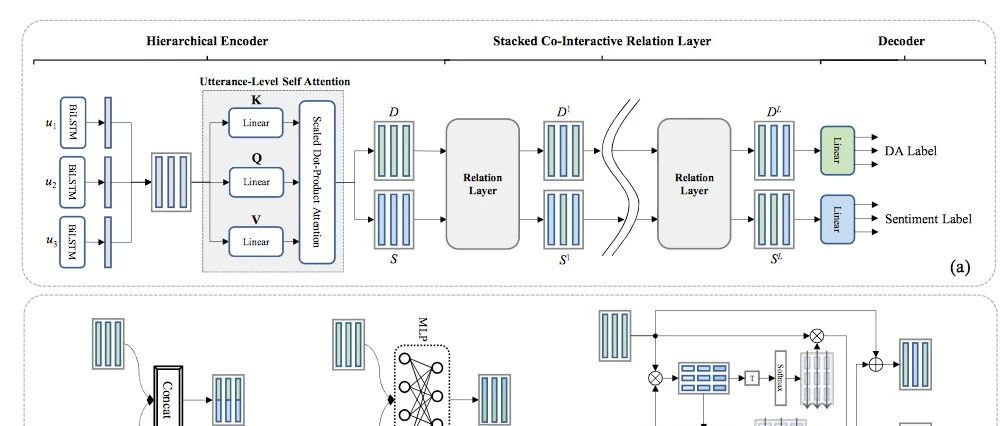
赛尔原创 | AAAI20 用于联合建模对话行为识别和情感分类的深度交互关系网络
本文录用于AAAI2020,首次显式地建模了对话行为识别和情感分类任务之间的交互和关系,并探索了三种交互函数,在公开数据集上达到了当时的SOTA效果。