新闻列表
赛尔原创@COLING2024 | 人工智能助手API调用能力的动态评估方法
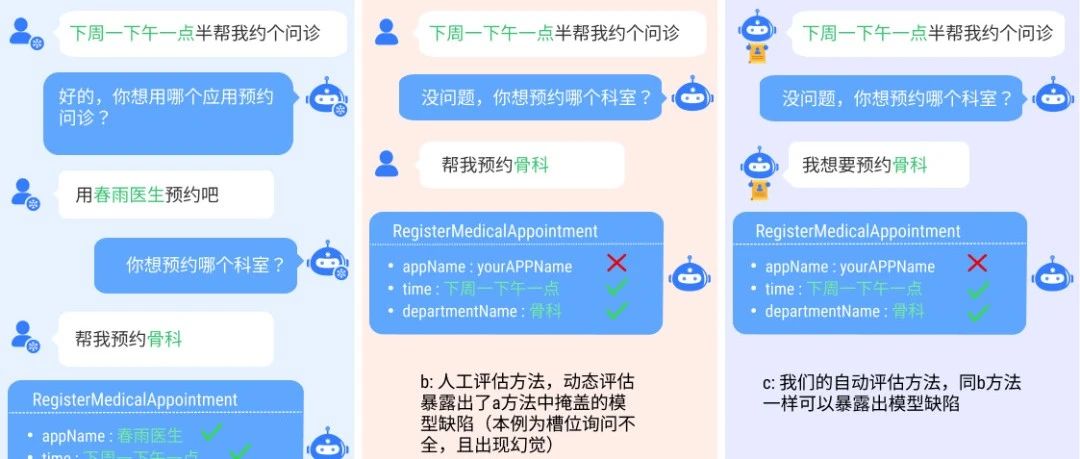
论文名称:Beyond Static Evaluation: A Dynamic Approach to Assessing AI Assistants’ API Invocation Capabilities 论文作者:牟虹霖,徐阳,冯云...
赛尔原创@COLING2024 | 面向编程的自然语言处理综述
本文围绕编程语言的两大核心特点:结构性和功能性,系统梳理了将自然语言处理技术应用于编程领域的研究进展,内容涵盖任务定义、数据集构建、评估方法、关键技术以及代表性模型等诸多方面,以期为读者全面展现这一新兴交叉领域的研究现状。
赛尔原创@COLING2024 | 面向编程的自然语言处理综述
本文围绕编程语言的两大核心特点:结构性和功能性,系统梳理了将自然语言处理技术应用于编程领域的研究进展,内容涵盖任务定义、数据集构建、评估方法、关键技术以及代表性模型等诸多方面,以期为读者全面展现这一新兴交叉领域的研究现状。赛尔原创@COLING2024 | LM-Combiner:通过模型改写实现更精准的语法纠错

语法纠错旨在识别并纠正文本中的常见语法错误。前人方法需要较多的计算资源并且损失了一部分召回率。本文通过改写单一校对系统的输出来过滤其中的过度纠正现象;同时由于经过针对性训练,对过度校对错误判断更准确,能够保证改写后的输出错误召回率保持不变。
赛尔原创@COLING2024 | LM-Combiner:通过模型改写实现更精准的语法纠错
语法纠错旨在识别并纠正文本中的常见语法错误。前人方法需要较多的计算资源并且损失了一部分召回率。本文通过改写单一校对系统的输出来过滤其中的过度纠正现象;同时由于经过针对性训练,对过度校对错误判断更准确,能够保证改写后的输出错误召回率保持不变。今日arXiv最热NLP大模型论文:做到头了!清华和哈工大把大模型量化做到了1比特

清华和哈工大提出了一个名为OneBit的1位量化感知训练框架把大模型量化做到了1比特,同时保证了时间和空间效率以及模型性能之间的平衡,至少能达到非量化性能的83%,而且训练过程还特别稳定。
今日arXiv最热NLP大模型论文:做到头了!清华和哈工大把大模型量化做到了1比特
清华和哈工大提出了一个名为OneBit的1位量化感知训练框架把大模型量化做到了1比特,同时保证了时间和空间效率以及模型性能之间的平衡,至少能达到非量化性能的83%,而且训练过程还特别稳定。哈工大开源“活字”对话大模型3.0版本

哈尔滨工业大学社会计算与信息检索研究中心(HIT-SCIR)近期推出了最新成果——活字3.0,致力于为自然语言处理的研究和实际应用提供更多可能性和选择。
哈工大开源“活字”对话大模型3.0版本
哈尔滨工业大学社会计算与信息检索研究中心(HIT-SCIR)近期推出了最新成果——活字3.0,致力于为自然语言处理的研究和实际应用提供更多可能性和选择。赛尔原创@AAAI 2024 |语义引导的生成式图像增广方法
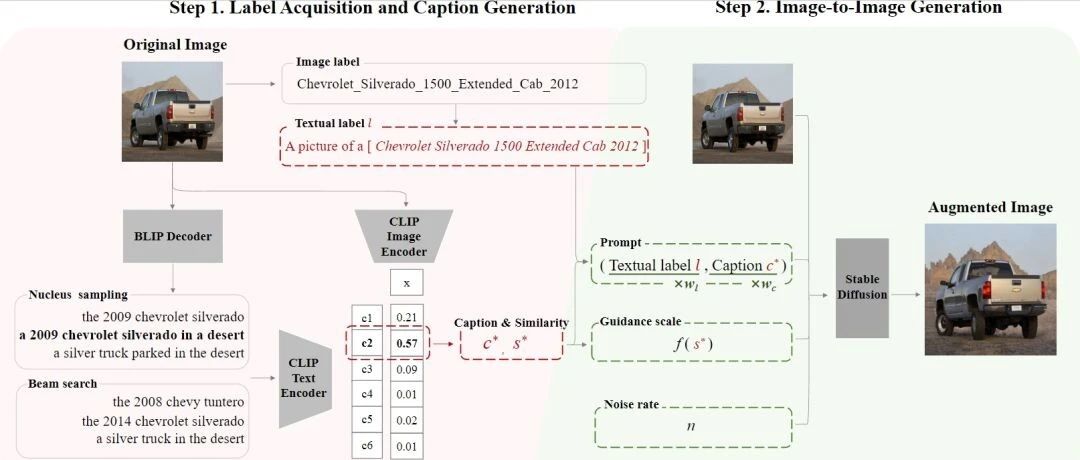
本文提出SGID,一种语义引导的生成式图像增广方法,用于在图像分类的数据增广中平衡增广图像的多样性和语义一致性,克服了以往的扰动式方法及生成式方法的局限。
赛尔原创@AAAI 2024 |语义引导的生成式图像增广方法
本文提出SGID,一种语义引导的生成式图像增广方法,用于在图像分类的数据增广中平衡增广图像的多样性和语义一致性,克服了以往的扰动式方法及生成式方法的局限。HIT-SCIR发布首个中文扩词表增量预训练混合专家模型Chinese-Mixtral-8x7B

哈工大社会计算与信息检索研究中心(HIT-SCIR)基于Mixtral-8x7B进行了中文扩词表增量预训练。扩充后的词表显著提高了模型对中文的编解码效率,通过大规模开源语料对扩词表模型进行增量预训练,使模型具备了强大的中文生成和理解能力。
HIT-SCIR发布首个中文扩词表增量预训练混合专家模型Chinese-Mixtral-8x7B
哈工大社会计算与信息检索研究中心(HIT-SCIR)基于Mixtral-8x7B进行了中文扩词表增量预训练。扩充后的词表显著提高了模型对中文的编解码效率,通过大规模开源语料对扩词表模型进行增量预训练,使模型具备了强大的中文生成和理解能力。赛尔笔记 | 面向表格数据的大模型推理综述
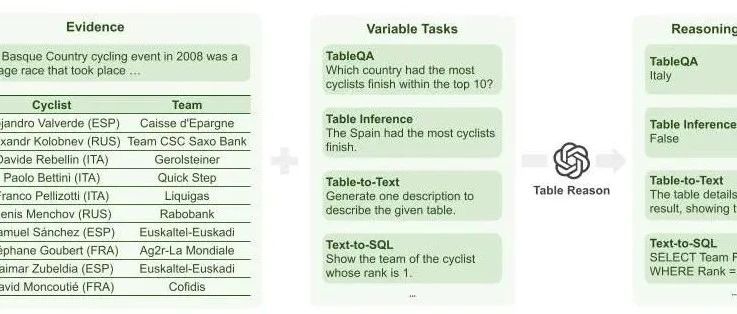
我们在本文对现有的基于LLM的表格推理相关工作进行梳理,来促进该领域上的研究。我们介绍表格推理任务的定义与主流数据集;我们给出基于LLM的表格推理方法的分类,并总结了该任务现有的研究工作;我们给出各个研究方向的可能改进,启发未来的研究思路。
赛尔笔记 | 面向表格数据的大模型推理综述
我们在本文对现有的基于LLM的表格推理相关工作进行梳理,来促进该领域上的研究。我们介绍表格推理任务的定义与主流数据集;我们给出基于LLM的表格推理方法的分类,并总结了该任务现有的研究工作;我们给出各个研究方向的可能改进,启发未来的研究思路。赛尔原创@EMNLP 2023 | 通过跨语言提示改进零样本 CoT 推理能力

本文引入了简单有效的CLP帮助思维链范式在不同语言间进行有效地对齐,并进一步提出了CLSP,利用不同语言专家的知识和不同语言间更加多样的思考方式,集成了多个推理路径,显著地提高了self-consistency的跨语言性能。
