新闻列表
哈工大SCIR 2023届29名同学顺利通过硕士答辩

2023年5月24日,哈尔滨工业大学社会计算与信息检索研究中心2023届29名同学顺利通过硕士答辩,获得工学或工程硕士学位。
哈工大SCIR三位博士生李家琦、袁建华、柳泽明顺利通过博士学位答辩

2023年5月26日上午,哈工大社会计算与信息检索研究中心王海峰教授指导的博士生柳泽明顺利通过博士学位论文答辩。赵铁军教授担任答辩委员会主席,王亚东教授、杨沐昀教授、车万翔教授、刘远超副教授、赵妍妍副教授和刘扬副教授担任答辩委员会成员,朱聪慧老师担任答辩秘书。
哈工大SCIR三位博士生李家琦、袁建华、柳泽明顺利通过博士学位答辩
2023年5月26日上午,哈工大社会计算与信息检索研究中心王海峰教授指导的博士生柳泽明顺利通过博士学位论文答辩。赵铁军教授担任答辩委员会主席,王亚东教授、杨沐昀教授、车万翔教授、刘远超副教授、赵妍妍副教授和刘扬副教授担任答辩委员会成员,朱聪慧老师担任答辩秘书。哈工大SCIR 13篇长文被ACL 2023主会/Findings录用

ACL年会是计算语言学和自然语言处理领域最重要的顶级国际会议,CCF A类会议,由计算语言学协会主办,每年举办一次。哈尔滨工业大学社会计算与信息检索研究中心有5篇长文被ACL 2023主会录用,8篇长文被Findings of ACL录用。
哈工大SCIR 13篇长文被ACL 2023主会/Findings录用
ACL年会是计算语言学和自然语言处理领域最重要的顶级国际会议,CCF A类会议,由计算语言学协会主办,每年举办一次。哈尔滨工业大学社会计算与信息检索研究中心有5篇长文被ACL 2023主会录用,8篇长文被Findings of ACL录用。哈工大自然语言处理研究所公开《ChatGPT调研报告》,内测哈工大“活字”对话大模型

2023年3月6日,哈工大自然语言处理研究所 ( HIT-NLP, since 1979 ) 师生联合撰写出《ChatGPT调研报告》(84页),对“大模型”技术进行了系统的介绍。此外,哈工大自然语言处理研究所已经研制出哈工大“活字”对话大模型(通用),目前处于研究所内测阶段。
哈工大自然语言处理研究所公开《ChatGPT调研报告》,内测哈工大“活字”对话大模型
2023年3月6日,哈工大自然语言处理研究所 ( HIT-NLP, since 1979 ) 师生联合撰写出《ChatGPT调研报告》(84页),对“大模型”技术进行了系统的介绍。此外,哈工大自然语言处理研究所已经研制出哈工大“活字”对话大模型(通用),目前处于研究所内测阶段。赛尔原创@AAAI 2023 | BridgeTower- 在视觉语言表示学习中建立编码器间的桥梁
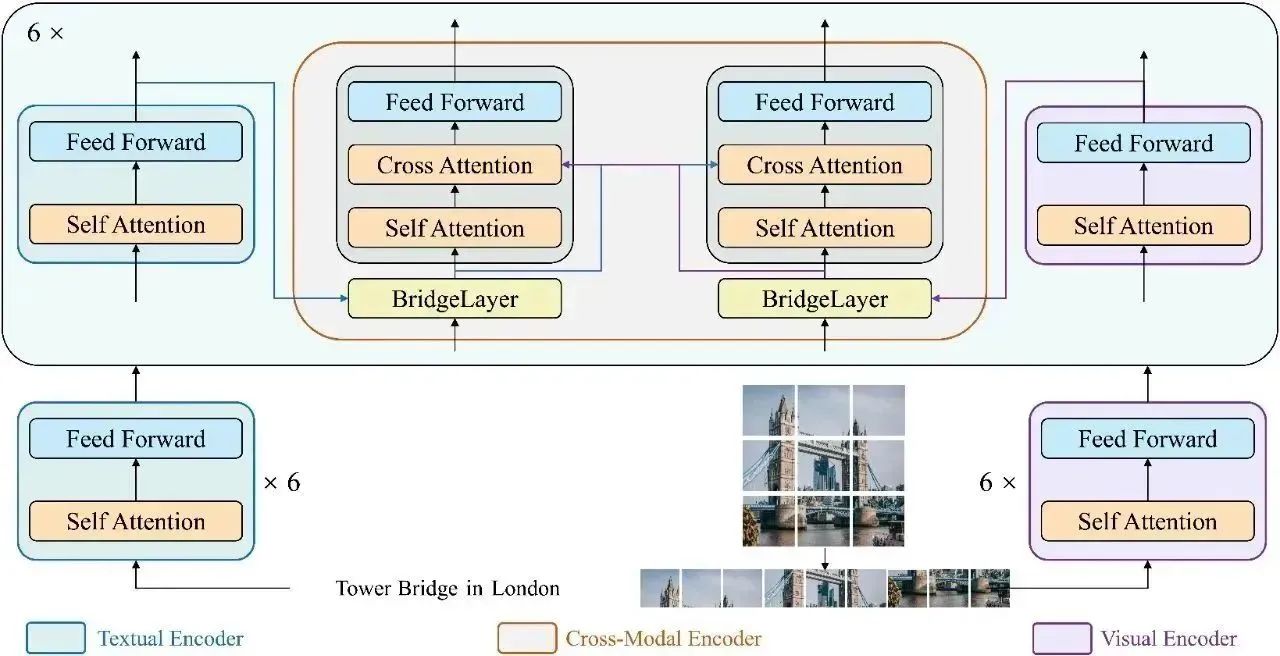
在本文中,我们提出了BridgeTower,它引入了多个BridgeLayer,在单模态编码器的顶层和跨模态编码器的每一层之间建立连接。这使得预训练单模态编码器中的不同语义层次的视觉和文本表示,通过BridgeLayer与跨模态表示进行融合,从而促进了跨模态编码器中,高效的,自下而上的跨模态对齐与融合。仅使用400万张图像进行视觉语言预训练,BridgeTower在各种下游的视觉-语言任务中取得了非常强大的性能。
赛尔原创@AAAI 2023 | BridgeTower- 在视觉语言表示学习中建立编码器间的桥梁
在本文中,我们提出了BridgeTower,它引入了多个BridgeLayer,在单模态编码器的顶层和跨模态编码器的每一层之间建立连接。这使得预训练单模态编码器中的不同语义层次的视觉和文本表示,通过BridgeLayer与跨模态表示进行融合,从而促进了跨模态编码器中,高效的,自下而上的跨模态对齐与融合。仅使用400万张图像进行视觉语言预训练,BridgeTower在各种下游的视觉-语言任务中取得了非常强大的性能。赛尔原创@COLING 2022 | 融合自适应机制与自训练框架的无监督文本顺滑方法
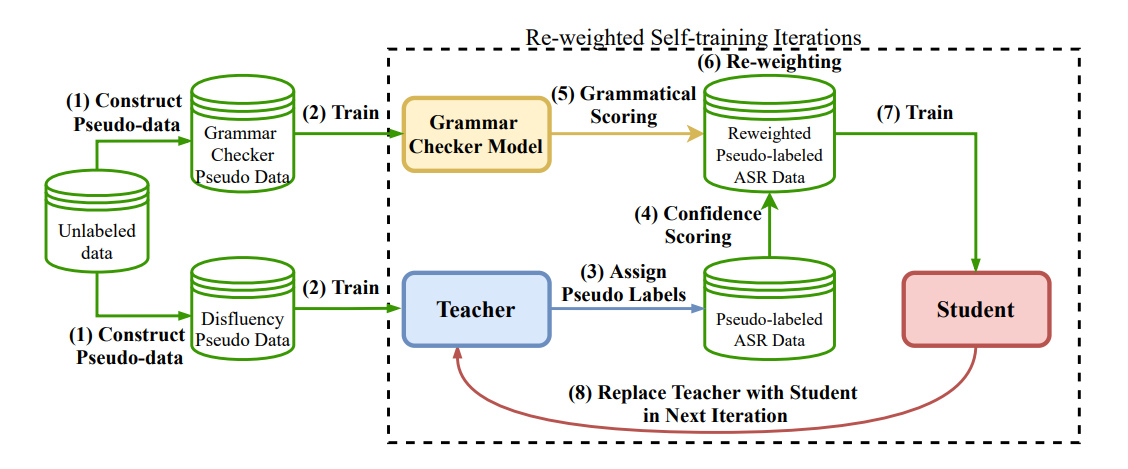
在这项工作中,我们提出了一种基于Re-weighting的自适应无监督训练框架来更好的解决文本顺滑任务。我们通过引入词级别置信与句子级别判别信息来赋予每个样本不同权重进行学习,同时采用更高效的基于对比的句对语法判别器,实现了一个更鲁棒、性能更好的无监督文本顺滑系统。实验表明,我们的优化方案能有效缓解选择偏差和错误累计的问题,在SWBD以及多个跨领域数据集上均有所提升。
赛尔原创@COLING 2022 | 融合自适应机制与自训练框架的无监督文本顺滑方法
在这项工作中,我们提出了一种基于Re-weighting的自适应无监督训练框架来更好的解决文本顺滑任务。我们通过引入词级别置信与句子级别判别信息来赋予每个样本不同权重进行学习,同时采用更高效的基于对比的句对语法判别器,实现了一个更鲁棒、性能更好的无监督文本顺滑系统。实验表明,我们的优化方案能有效缓解选择偏差和错误累计的问题,在SWBD以及多个跨领域数据集上均有所提升。赛尔原创@COLING 2022 | MetaPrompting:基于元学习的soft prompt初始化方法

本文提出了MetaPrompting,将基于优化的元学习方法推广到soft prompt模型中,来处理少标注文本任务。MetaPrompting利用源领域数据进行元学习,搜索能够更快、更好地适应于新的少标注人物的模型参数初始化点。在4个少标注文本分类数据集上的实验结果表明,MetaPrompting相比于朴素的soft prompt模型以及其他基于元学习的基线模型取得了更好的效果,达到了新的SOTA性能。
赛尔原创@COLING 2022 | MetaPrompting:基于元学习的soft prompt初始化方法
本文提出了MetaPrompting,将基于优化的元学习方法推广到soft prompt模型中,来处理少标注文本任务。MetaPrompting利用源领域数据进行元学习,搜索能够更快、更好地适应于新的少标注人物的模型参数初始化点。在4个少标注文本分类数据集上的实验结果表明,MetaPrompting相比于朴素的soft prompt模型以及其他基于元学习的基线模型取得了更好的效果,达到了新的SOTA性能。赛尔原创@COLING 2022 | CCTC:面向中文母语使用者的跨句子文本纠错数据集

中文文本纠错(Chinese Text Correction, CTC)主要针对中文拼写错误和语法错误进行检测和纠正。目前大部分中文拼写纠错和语法纠错的测试集都是单句级别的,并且是由外国的汉语学习者撰写的。我们发现中文母语使用者犯的错误和非母语使用者犯的错误有很大的不同,直接使用目前已有的一些数据集作为测试集来为面向中文母语使用者准备的校对系统进行评测并不合适。此外,一些错误通常还需要上下文信息来进行检测和纠正。在本文中,我们提出了一个基于中文母语使用者撰写文本的跨句子中文文本纠错测试集CCTC。
赛尔原创@COLING 2022 | CCTC:面向中文母语使用者的跨句子文本纠错数据集
中文文本纠错(Chinese Text Correction, CTC)主要针对中文拼写错误和语法错误进行检测和纠正。目前大部分中文拼写纠错和语法纠错的测试集都是单句级别的,并且是由外国的汉语学习者撰写的。我们发现中文母语使用者犯的错误和非母语使用者犯的错误有很大的不同,直接使用目前已有的一些数据集作为测试集来为面向中文母语使用者准备的校对系统进行评测并不合适。此外,一些错误通常还需要上下文信息来进行检测和纠正。在本文中,我们提出了一个基于中文母语使用者撰写文本的跨句子中文文本纠错测试集CCTC。哈工大SCIR十篇长文被EMNLP 2022主会及子刊录用

EMNLP是计算语言学和自然语言处理领域顶级国际会议之一,CCF B类会议,由ACL SIGDAT(语言学数据特殊兴趣小组)主办,每年举办一次。哈尔滨工业大学社会计算与信息检索研究中心有10篇长文被录用,其中7篇被主会录用,3篇被Findings of EMNLP子刊录用。
哈工大SCIR十篇长文被EMNLP 2022主会及子刊录用
EMNLP是计算语言学和自然语言处理领域顶级国际会议之一,CCF B类会议,由ACL SIGDAT(语言学数据特殊兴趣小组)主办,每年举办一次。哈尔滨工业大学社会计算与信息检索研究中心有10篇长文被录用,其中7篇被主会录用,3篇被Findings of EMNLP子刊录用。哈工大SCIR取得CCIR Cup 2022混合表格与文本数据问答赛道冠军
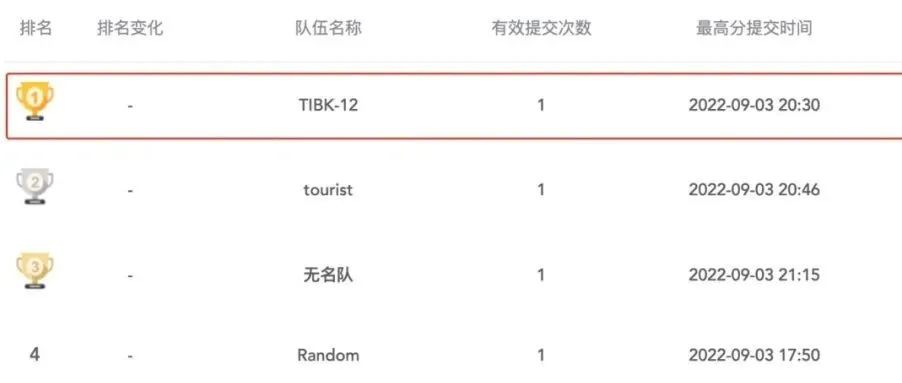
哈工大SCIR的“TIBK-12”小队以75.1的成绩夺得全国信息检索挑战杯-基于金融财报中的混合表格与文本数据的问答赛道冠军。团队成员包括窦隆绪、王丁子睿,指导教师为车万翔教授。