新闻列表
哈工大SCIR两位博士生施晓明、侯宇泰顺利通过博士学位答辩
2022年9月5日上午,哈工大社会计算与信息检索研究中心两位博士生施晓明、侯宇泰顺利通过博士学位论文答辩。
语言技术平台(LTP)推出 v4.2 版本!
推出 v4.2 版本!.jpg)
语言技术平台(LTP)推出 v4.2 版本,此次升级主要提升了分词等常用任务的推理速度、增加了平台的易用性等。
语言技术平台(LTP)推出 v4.2 版本!
语言技术平台(LTP)推出 v4.2 版本,此次升级主要提升了分词等常用任务的推理速度、增加了平台的易用性等。哈工大SCIR在MMNLU-22多语言任务型对话自然语言理解评测取得Full Dataset赛道第一名
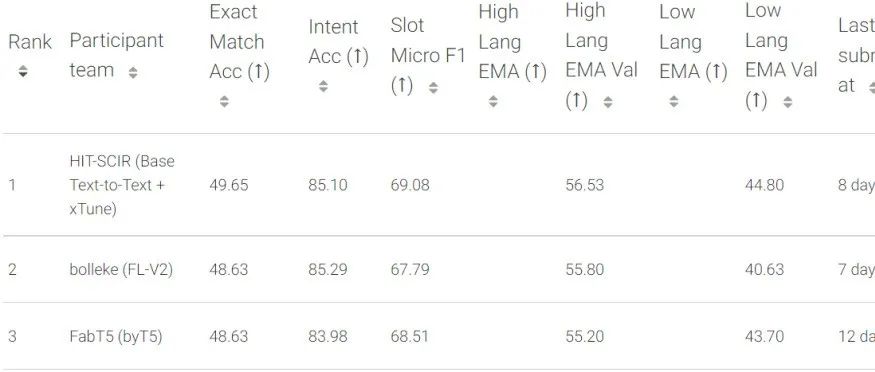
HIT-SCIR语言分析组郑博、黎州扬、魏福煊、陈麒光、覃立波组成的团队(指导教师车万翔教授)参加MMNLU-22评测,在Full Dataset赛道中获得第一名,在Zero-Shot赛道中获得第二名。
哈工大SCIR在MMNLU-22多语言任务型对话自然语言理解评测取得Full Dataset赛道第一名
HIT-SCIR语言分析组郑博、黎州扬、魏福煊、陈麒光、覃立波组成的团队(指导教师车万翔教授)参加MMNLU-22评测,在Full Dataset赛道中获得第一名,在Zero-Shot赛道中获得第二名。ACL@2022 | 反向预测更好?基于反向提示的小样本槽位标注方法

本文录用于ACL 2022 Findings。提示学习方法在如槽位标注等词级别任务上十分低效。本文探索了一种反向提示方法,并提出了迭代预测策略来建模标签之间的依赖关系。我们的方法在多个数据集上均有提升,并大幅加快了槽位标注的预测速度。
ACL@2022 | 反向预测更好?基于反向提示的小样本槽位标注方法
本文录用于ACL 2022 Findings。提示学习方法在如槽位标注等词级别任务上十分低效。本文探索了一种反向提示方法,并提出了迭代预测策略来建模标签之间的依赖关系。我们的方法在多个数据集上均有提升,并大幅加快了槽位标注的预测速度。哈工大SCIR车万翔、刘挺 | 自然语言处理新范式:基于预训练模型的方法

近日,《中兴通讯技术》2022年第2期专题——《自然语言处理预训练模型》正式发表,受本期专题策划人,清华大学计算机系教授、中国工程院院士郑纬民邀请,我中心车万翔、刘挺教授撰文,介绍了《自然语言处理新范式:基于预训练模型的方法》。
哈工大SCIR车万翔、刘挺 | 自然语言处理新范式:基于预训练模型的方法
近日,《中兴通讯技术》2022年第2期专题——《自然语言处理预训练模型》正式发表,受本期专题策划人,清华大学计算机系教授、中国工程院院士郑纬民邀请,我中心车万翔、刘挺教授撰文,介绍了《自然语言处理新范式:基于预训练模型的方法》。赛尔原创@AAAI 2022|基于Profile信息的口语语言理解基准
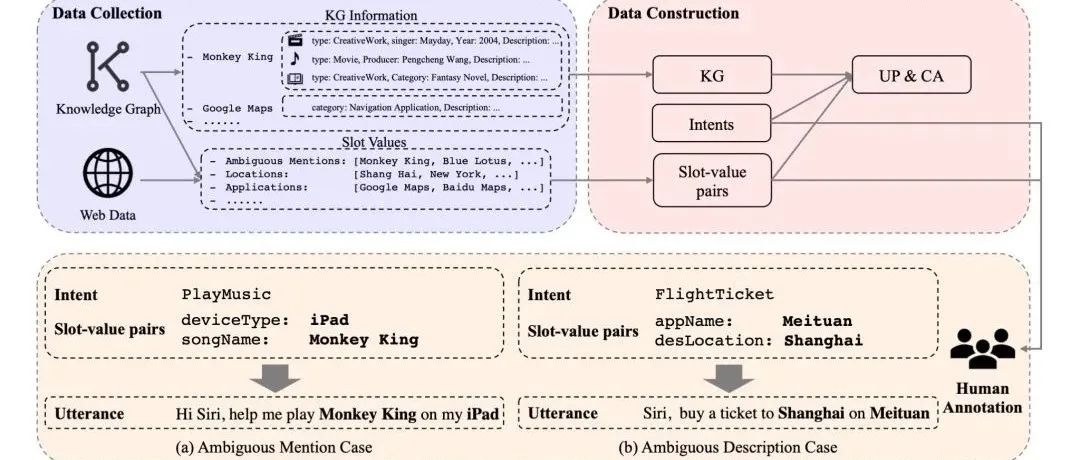
本文录用于AAAI 2022。本文研究基于Profile的口语语言理解任务。本文标注了约含五千条数据的中文数据集,并使用多层次知识适配器来有效引入辅助Profile信息,实验表明,该方式能够有效提升SLU模型在ProSLU任务上的表现。
赛尔原创@AAAI 2022|基于Profile信息的口语语言理解基准
本文录用于AAAI 2022。本文研究基于Profile的口语语言理解任务。本文标注了约含五千条数据的中文数据集,并使用多层次知识适配器来有效引入辅助Profile信息,实验表明,该方式能够有效提升SLU模型在ProSLU任务上的表现。赛尔原创@EMNLP 2021 | 多语言和跨语言对话推荐
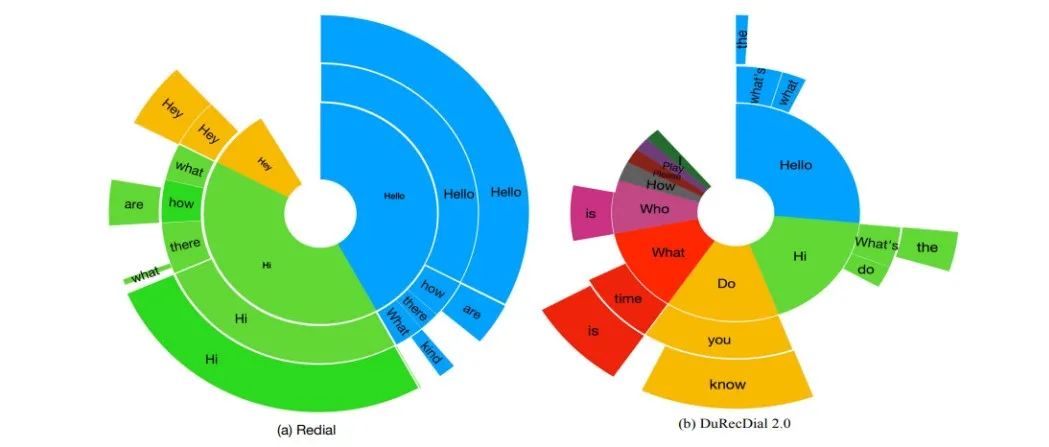
本文录用于EMNLP 2021。为促进多语言和跨语言对话推荐的研究,我们构建了第一个中英双语并行对话推荐数据集DuRecDial 2.0,并定义了5个任务。自动评估和人工评估结果表明,使用英文对话推荐数据可以提高中文对话推荐的性能。
赛尔原创@EMNLP 2021 | 多语言和跨语言对话推荐
本文录用于EMNLP 2021。为促进多语言和跨语言对话推荐的研究,我们构建了第一个中英双语并行对话推荐数据集DuRecDial 2.0,并定义了5个任务。自动评估和人工评估结果表明,使用英文对话推荐数据可以提高中文对话推荐的性能。赛尔原创@EMNLP 2021 | 预训练跨语言模型中的大词表构建及使用
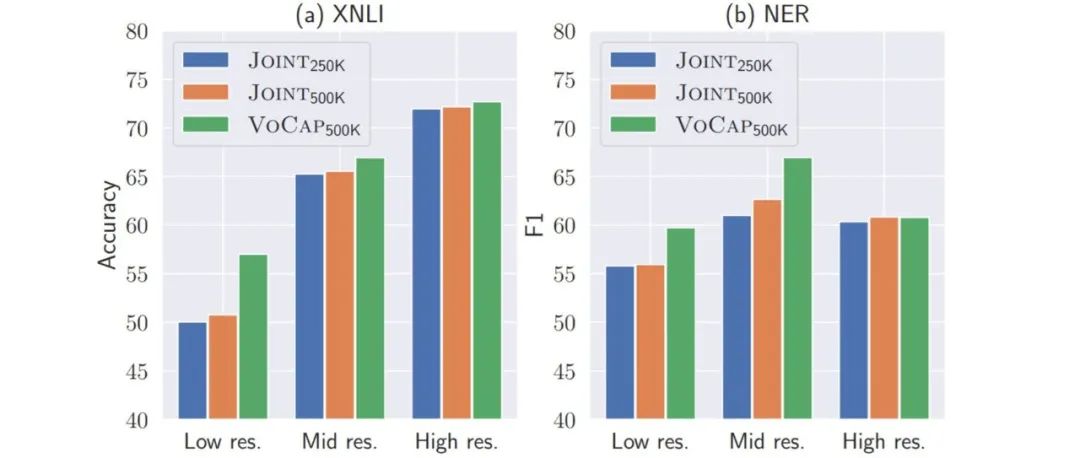
本文录用于EMNLP 2021。本文首先提出VoCap词表构建算法以构建更大的多语言词表,综合考虑每种语言的语言特定词汇能力及预训练语料大小为每种语言分配合适的词表大小。实验结果表明,基于VoCap方法构建的多语言词表要优于之前的方法。
赛尔原创@EMNLP 2021 | 预训练跨语言模型中的大词表构建及使用
本文录用于EMNLP 2021。本文首先提出VoCap词表构建算法以构建更大的多语言词表,综合考虑每种语言的语言特定词汇能力及预训练语料大小为每种语言分配合适的词表大小。实验结果表明,基于VoCap方法构建的多语言词表要优于之前的方法。赛尔原创@ACL Findings | 任务共舞,小样本场景下的多任务联合学习方法初探

本文录用于Findings of ACL 2021。现有Few-shot模型通常一次只学习一个单一任务,如何在少样本情景下联合学习多个任务的方法还少有研究。本文针对这一问题提出了“共舞”(ConProm)模型,大幅提升了联合准确率。
赛尔原创@ACL Findings | 任务共舞,小样本场景下的多任务联合学习方法初探
本文录用于Findings of ACL 2021。现有Few-shot模型通常一次只学习一个单一任务,如何在少样本情景下联合学习多个任务的方法还少有研究。本文针对这一问题提出了“共舞”(ConProm)模型,大幅提升了联合准确率。哈工大SCIR取得国家电网调控AI创新大赛赛道2(Text2SQL)冠军
冠军.jpg)
近日,来自哈工大社会计算与信息检索研究中心(HIT-SCIR)的“赛尔小队”以68.75的成绩夺得国家电网调控人工智能创新大赛-电网运行信息智能检索赛道(Text2SQL)冠军。团队成员包括窦隆绪、潘名扬、王丁子睿,指导教师为车万翔教授。