新闻列表
赛尔原创@AAAI 2021 | 数据增强没效果?试试用Cluster-to-Cluster生成更多样化的新数据吧

本文录用于AAAI 2021。我们提出了一种全新的多到多生成模型C2C-GenDA来实现数据增强。在数据不足的情景下,这种新的生成范式在两个公开数据集上分别带来了7.99 (11.9%↑) 和5.76 (13.6%↑) F1的提升。
哈工大SCIR多位师生受邀参加第一届中国自然语言处理学生研讨会(CSSNLP 2020)
.jpg)
第一届中国自然语言处理学生研讨会顺利召开,我中心车万翔教授进行了题为“基于小样本学习的自然语言处理”的报告;我中心覃立波同学进行了题为“初探迁移学习在任务型对话系统中的应用”报告;王雪松同学任前沿主题研讨会主席。
哈工大SCIR多位师生受邀参加第一届中国自然语言处理学生研讨会(CSSNLP 2020)
第一届中国自然语言处理学生研讨会顺利召开,我中心车万翔教授进行了题为“基于小样本学习的自然语言处理”的报告;我中心覃立波同学进行了题为“初探迁移学习在任务型对话系统中的应用”报告;王雪松同学任前沿主题研讨会主席。哈工大SCIR三篇长文被AAAI 2021录用

2021年的首个人工智能顶级会议 AAAI 2021 将于美国纽约举办,时间在 2021年2 月 2 日至 9 日,本届大会将是第 35 届 AAAI 大会。
AAAI 的英文全称是 Association for the Advance...
哈工大SCIR三篇长文被AAAI 2021录用
2021年的首个人工智能顶级会议 AAAI 2021 将于美国纽约举办,时间在 2021年2 月 2 日至 9 日,本届大会将是第 35 届 AAAI 大会。 AAAI 的英文全称是 Association for the Advance...赛尔原创@AAAI2021 | 小样本学习下的多标签分类问题初探

本文录用与AAAi 2021。小样本学习(Few-shot Learning)近年来吸引了大量的关注,但是针对多标签问题(Multi-label)的研究还相对较少。在本文中,我们以用户意图检测任务为切入口,研究了的小样本多标签分类问题。
赛尔原创@AAAI2021 | 小样本学习下的多标签分类问题初探
本文录用与AAAi 2021。小样本学习(Few-shot Learning)近年来吸引了大量的关注,但是针对多标签问题(Multi-label)的研究还相对较少。在本文中,我们以用户意图检测任务为切入口,研究了的小样本多标签分类问题。赛尔原创@Findings | 基于动态图交互网络的多意图口语语言理解框架
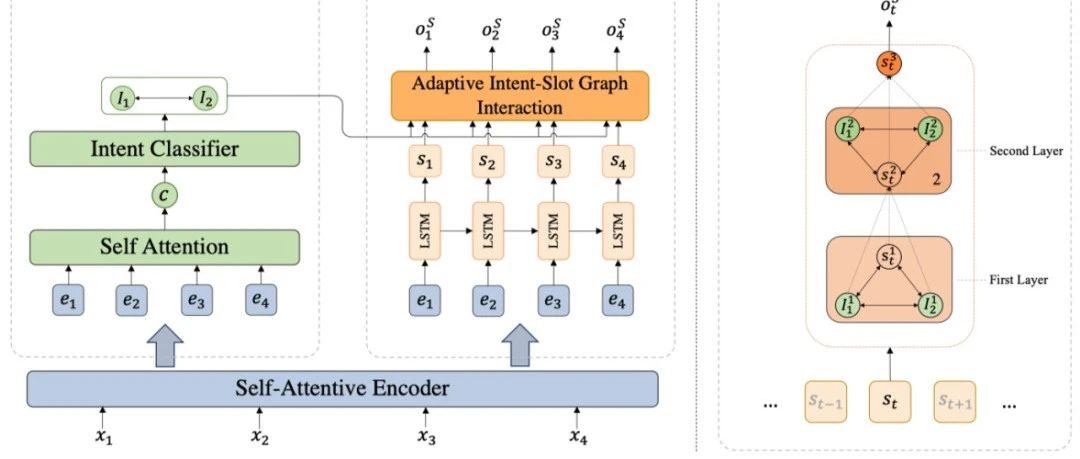
本文录用于Findings of EMNLP2020, 针对多意图SLU任务,提出一种自适应图交互网络来自动捕获相关意图信息来进行每个单词的槽位填充。该模型在三个数据集上达到SOTA,在单意图数据集上超过前人模型,进一步验证模型的有效性。
赛尔原创@Findings | 基于动态图交互网络的多意图口语语言理解框架
本文录用于Findings of EMNLP2020, 针对多意图SLU任务,提出一种自适应图交互网络来自动捕获相关意图信息来进行每个单词的槽位填充。该模型在三个数据集上达到SOTA,在单意图数据集上超过前人模型,进一步验证模型的有效性。赛尔原创@Findings | 中文预训练语言模型回顾
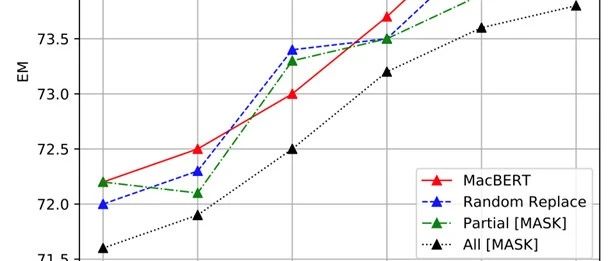
本文录用于Findings of EMNLP 2020。本文将主流预训练模型应用于中文场景并进行深度对比,并提出了基于文本纠错的预训练语言模型MacBERT,解决了预训练模型中“预训练-精调”不一致的问题,在多个中文任务上获得显著性能提升。
赛尔原创@Findings | 中文预训练语言模型回顾
本文录用于Findings of EMNLP 2020。本文将主流预训练模型应用于中文场景并进行深度对比,并提出了基于文本纠错的预训练语言模型MacBERT,解决了预训练模型中“预训练-精调”不一致的问题,在多个中文任务上获得显著性能提升。赛尔原创@EMNLP 2020 | 且回忆且学习:在更少的遗忘下精调深层预训练语言模型

本文录用于EMNLP 2020。本文提出且回忆且学习的机制,通过采用多任务学习同时学习预训练任\x0a务和目标任务,提出了预训练模拟机制和迁移机制。实验表明文章提出的方法在GLUE上达到了最优性能。
赛尔原创@EMNLP 2020 | 且回忆且学习:在更少的遗忘下精调深层预训练语言模型
本文录用于EMNLP 2020。本文提出且回忆且学习的机制,通过采用多任务学习同时学习预训练任\x0a务和目标任务,提出了预训练模拟机制和迁移机制。实验表明文章提出的方法在GLUE上达到了最优性能。赛尔原创|EMNLP 2020 融合自训练和自监督方法的无监督文本顺滑研究

本文录用于EMNLP 2020。在自然语言处理中,顺滑任务的目是识别出话语中自带的不流畅现象。本文融合了自训练和自监督两种学习方法,探索无监督的文本顺滑方法。实验结果表明,本方法在不使用有标注数据进行训练的情况下,取得了非常不错的性能。
赛尔原创|EMNLP 2020 融合自训练和自监督方法的无监督文本顺滑研究
本文录用于EMNLP 2020。在自然语言处理中,顺滑任务的目是识别出话语中自带的不流畅现象。本文融合了自训练和自监督两种学习方法,探索无监督的文本顺滑方法。实验结果表明,本方法在不使用有标注数据进行训练的情况下,取得了非常不错的性能。哈工大SCIR九篇长文被EMNLP 2020及子刊录用
EMNLP 2020(2020 Conference on Empirical Methods in Natural Language Processing)将于2020年11月16日至20日以在线会议的形式举办。EMNLP是计算语言学和自...
哈工大SCIR九篇长文被EMNLP 2020及子刊录用
EMNLP 2020(2020 Conference on Empirical Methods in Natural Language Processing)将于2020年11月16日至20日以在线会议的形式举办。EMNLP是计算语言学和自...哈工大SCIR六篇文章被COLING 2020录用
COLING 2020, the 28th International Conference on Computational Linguistics将于2020年12月8日至13日在线举行。COLING是自然语言处理领域的重要国际会议,每...