SemEval-2016 Task 9中文语义依存图数据对外发布
2018年04月10日哈工大社会计算与信息检索研究中心与北京语言大学邵艳秋教授合作,于2016年组织了SemEval-2016 Task 9中文语义依存评测(http://alt.qcri.org/semeval2016/task9/),为促进相关领域的研究发展,我们于近日正式对外发布此次评测所使用的数据集,可以在https://github.com/HIT-SCIR/SemEval-2016获得。欢迎大家下载使用该数据集,也欢迎提出任何意见和建议。
我们在该数据集上的最新研究已发表于AAAI 2018,具体信息可以参考论文:
Yuxuan Wang, Wanxiang Che, Jiang Guo and Ting Liu. 2018. A Neural Transition-Based Approach for Semantic Dependency Graph Parsing. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence (AAAI2018).
另外,我们基于该数据集实现的中文语义依存图分析器已经纳入LTP(http://ltp.ai/)之中,也欢迎大家使用。
下面我们将对中文语义依存图的概念以及此次发布的SemEval-2016 Task 9数据集进行具体介绍。
1. 中文语义依存图介绍
要让机器能够理解自然语言,需要对原始文本自底向上进行分词、词性标注、命名实体识别和句法分析,若想要机器更智能,像人一样理解和运用语言,还需要对句子进行更深一层的分析,即句子级语义分析。
语义依存分析是通往语义深层理解的一条蹊径,它通过在句子结构中分析实词间的语义关系(这种关系是一种事实上或逻辑上的关系,且只有当词语进入到句子时才会存在)来回答句子中“谁在何时对谁做了什么”等问题。例如句子“张三昨天告诉李四一个秘密”,语义依存分析可以回答四个问题,即谁告诉了李四一个秘密,张三告诉谁一个秘密,张三什么时候告诉李四一个秘密,张三告诉李四什么。

图1 语义依存表示示例
图1中表示语义的形式为依存形式,Agt表示施事、Cont表示内容等。其优势在于形式简洁,易于理解和运用。语义依存分析建立在依存理论基础上,是对语义的深层分析。可分为两个阶段,首先是根据依存语法建立依存结构,即找出句子中的所有修饰词与核心词对,然后再对所有的修饰词与核心词对指定语义关系。可见,语义依存分析可以同时描述句子的结构和语义信息。
语义分析可以跨越句子的表层结构直接获取深层语义表达的本质,例如句子:“昨天,张三将一个秘密告诉李四。”,虽然它和图1中的句子表述形式不同,但含义相同,具体见图2。这种性质在信息检索、机器翻译等诸多领域有重要作用。

图2 语义依存表示示例
同时,由于中文严重缺乏形态的变化,词类与句法成分没有严格的对应关系,导致中文句法分析的精度始终不高。目前英文在标准测试集上的句法分析准确率达到90%左右,而中文只能达到80%左右。既然中文是意合的,在形式分析上有劣势,因此我们提出发挥中文意合的特点,跨越句法分析直接进行语义依存分析。
我中心于2016年与北京语言大学邵艳秋教授合作在SemEval-2012 Task 5中文语义依存树数据集的基础上针对其语义关系彼此易混淆、语义关系数量太大,有些关系在标注语料中出现次数很少;依存树结构,刻画语义不全面等问题,扩展了语义依存的表示形式,提出了中文语义依存图,在必要时突破树形结构。这样的突破使得对连动、兼语、概念转位等汉语中常见的现象的分析更全面深入,当然这也给依存分析器的构建带来了很大的难度,因为任何词都可能有多个父节点。图3直观地展示了语义依存树与依存图的区别。
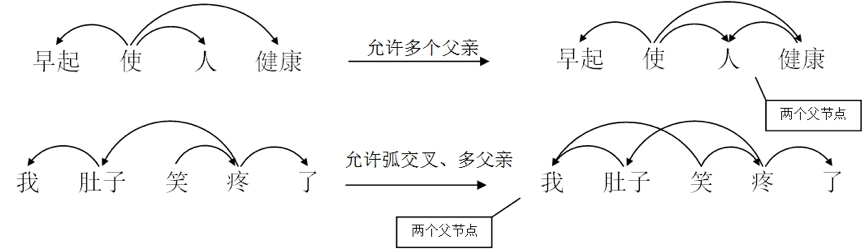
图3 语义依存树与语义依存图对比示例
语义依存树与语义依存图的主要区别在于,在依存树中,任何一个成分都不能依存于两个或两个以上的成分,而在依存图中则允许句中成分依存于两个或两个以上的成分。且在依存图中允许依存弧之间存在交叉,而依存树中不允许。
语义依存图的标注中压缩了语义关系类型的数量,重新组织并缩减了语义关系,将关系分为主要语义角色、事件关系、关系标记,从而减少不必要的类间关系混淆。
2. 数据集介绍
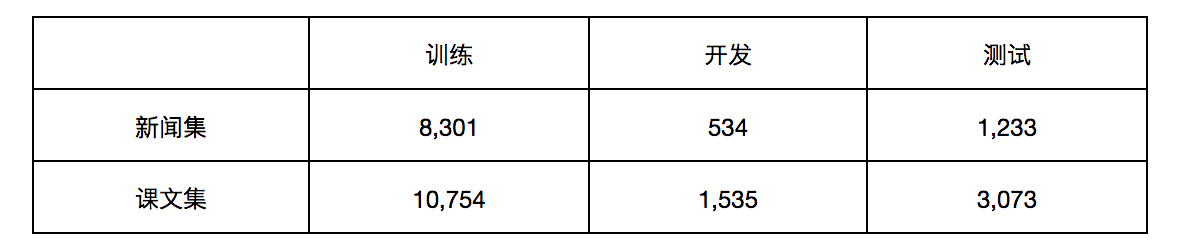
SemEval-2016 Task 9中文语义依存图数据集,包含10,068句新闻句子(NEWS)和15,362句课文句子(TEXTBOOKS)。新闻句子平均长度是31个词,课文句子平均长度是14个词。具体的数据划分如表1所示。
表1 中文语义依存图数据集数据划分
数据格式采用CoNLLX格式,如图4所示,其中第1列是词序号,第2列是词,第4列是词性,第7列是父节点序号(0表示父节点为虚拟根节点),第8列是当前词与父节点之间的语义关系(弧标签)。(在CoNLLX格式中第3列是词根,由于中文没有词根信息因此与第2列相同。第4、5列分别是粗粒度和细粒度词性,这里只有一种词性,因此这两列相同。)用多个具有相同词序号的行表示多父节点情况,每一行记录该词一个父节点的信息。例如图4中“人”有两个父节点,分别是序号为2的“使”和序号为4的“健康”,因此数据中序号为3的“人”占了2行。

图4 数据格式示例
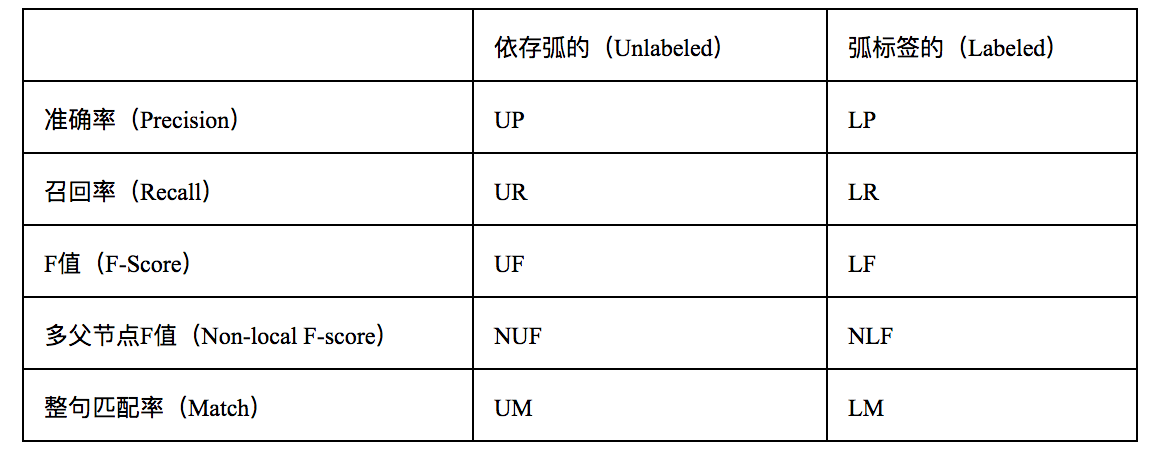
SemEval-2016 Task 9评测的评测指标如表2所示,其中最重要的两项是LF和NLF,分别代表了整体的弧标签F值和多父节点词的弧标签F值,其中后者对于图结构分析尤为重要,因为只有图结构中才允许多父节点词的出现。评测最终以LF值作为系统排名依据。
表2 评测指标