哈工大SCIR在CoNLL-2019国际跨框架语义分析评测中取得第一名
2019年08月13日在刚刚结束的CoNLL-2019国际跨框架语义分析评测(http://mrp.nlpl.eu/)中,哈工大社会计算与信息检索研究中心(HIT-SCIR)取得了第一名的好成绩,这是SCIR实验室继取得CoNLL-2018国际多语言通用依存分析评测第一名后再次取得该国际技术评测的冠军。
CoNLL 系列评测每年由 ACL 的计算自然语言学习会议(Conference on Computational Natural Language Learning,CoNLL) 主办,是自然语言处理领域影响力最大的国际技术评测,有力推动了自然语言处理各项任务的发展。
今年的 CoNLL 任务为:Cross-Framework Meaning Representation Parsing,即跨框架语义分析。涵盖了DM、PSD、EDS、UCCA、AMR等5种最为著名的语义表示框架,每种框架都将自然语言表示成图结构来表达特定的语义特性。5个框架按照图中结点与句子中的词的对齐关系,大致可以分为3类:
- 图中的结点与句子中的词一一对应(DM、PSD)
- 图中存在虚结点,其与句子的词构成一对多(UCCA)、或者多对多的对应关系(EDS)
- 图中存在虚结点,但是和句子的词之间没有显式的对齐关系(AMR)
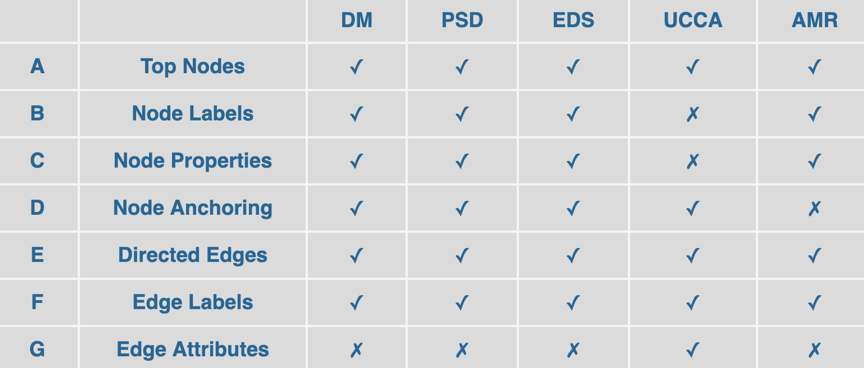
本次评测统一了5种框架的表示方法,与之对应的,也统一了评测的方法。具体来说,在评价每个系统表现的时候,需要计算标准图与预测图的同构程度,并考虑以下7项与语义图相关的属性:头结点、每个结点的标签、每个结点的特性(词性、词干)、结点对应句子中字符的范围(锚点)、有向边的集合、每条边上的标签、每条边上的属性(UCCA区分实边和虚边)。从下图可以看到,每个框架只对应若干个图的属性。在进行排名的时候,组织者将会计算每个参赛系统在5个框架下的表现,即按照每个框架所对应的属性,计算标准图与预测图之间的的匹配程度(F1)。最后将所有的框架在所有属性的匹配分数汇总起来,记为ALL-F1值,作为参赛系统的性能指标。
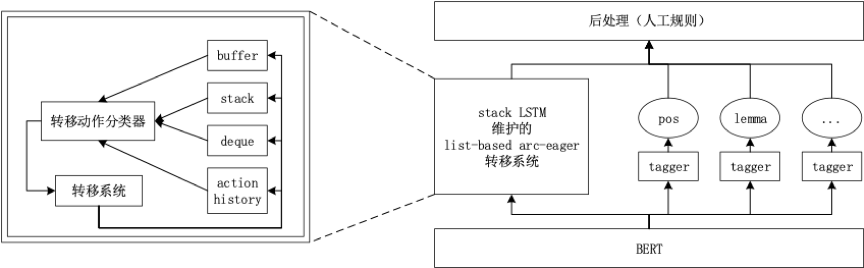
我们采用基于转移的方法设计了参赛系统,并且使用了预训练语言模型BERT来增强词的上下文表示,通过加入Deque结构或加入SWAP操作处理了交叉边的现象,并针对转移系统中用到的Buffer、Stack、Deque等数据结构设计了一个新的批次训练方法,提高了训练速度。详细的系统实现可以参考我们之后发布在CoNLL2019上的评测系统描述。
最终的ALL-F1排名如下:
