LTP 4.0!单模型完成6项自然语言处理任务
2020年06月15日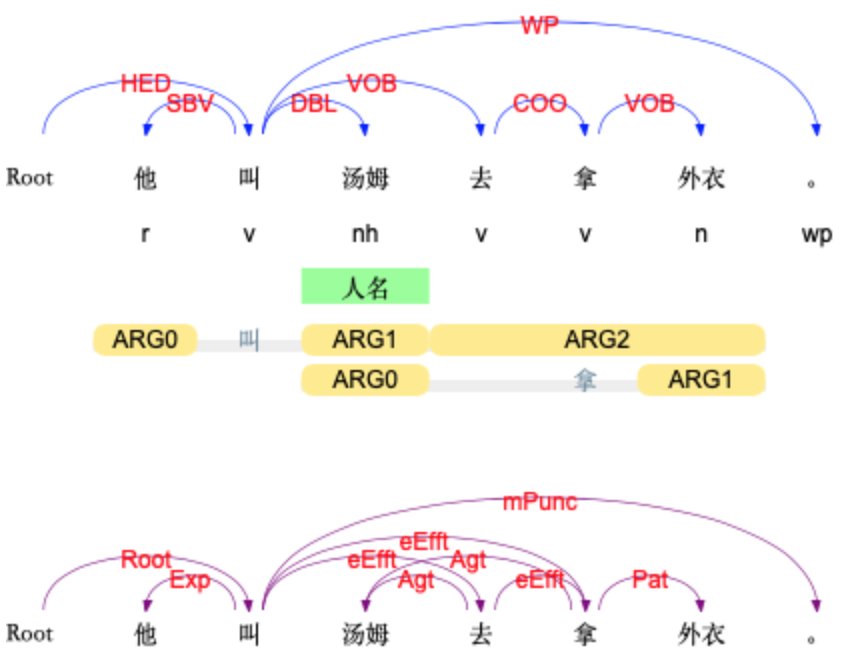
语言技术平台(Language Technology Platform, LTP)是哈工大社会计算与信息检索研究中心(HIT-SCIR)历时多年研发的一整套高效、高精度的中文自然语言处理开源基础技术平台。该平台集词法分析(分词、词性标注、命名实体识别)、句法分析(依存句法分析)和语义分析(语义角色标注、语义依存分析)等多项自然语言处理技术于一体。其中句法分析、语义分析等多项关键技术多次在CoNLL国际评测中获得了第1名。此外,平台还荣获了2010年中国中文信息学会科学技术一等奖、2016年黑龙江省科技进步一等奖。国内外众多研究单位和知名企业通过签署协议以及收费授权的方式使用该平台。
- 基于多任务学习框架进行统一学习,使得全部六项任务可以共享语义信息,达到了知识迁移的效果。既有效提升了系统的运行效率,又极大缩小了模型的占用空间
- 基于预训练模型进行统一的表示 ,有效提升了各项任务的准确率
- 基于教师退火模型蒸馏出单一的多任务模型,进一步提高了系统的准确率
- 基于PyTorch框架开发,提供了原生的Python调用接口,通过pip包管理系统一键安装,极大提高了系统的易用性

为了模型的小巧易用,本次发布的版本基于哈工大讯飞联合实验室发布的中文ELECTRA Small预训练模型。后续将陆续发布基于不同预训练模型的版本,从而为用户提供更多准确率和效率平衡点的选择。
测试环境如下:
- Python 3.7
- LTP 4.0 Batch Size = 1
- CentOS 3.10.0-1062.9.1.el7.x86_64
-
Intel(R) Xeon(R) CPU E5-2640 v4 @ 2.40GHz
备注:速度数据在人民日报命名实体测试数据上获得,速度计算方式均为所有任务顺序执行的结果。另外,语义角色标注与语义依存新旧版采用的语料不相同,因此无法直接比较(新版语义依存使用SemEval 2016语料,语义角色标注使用CTB语料)。