哈工大SCIR Poster交流大会顺利举办
2021年01月13日
2020年1月8日14:00,哈尔滨工业大学社会计算与信息检索研究中心(哈工大SCIR)举行了Poster交流大会。
自2019年7月以来,哈工大SCIR每学期举办一次学术Poster交流大会,如今已举行至第四届。本活动的初衷是在提升学生自身综合素质以及学术热情的同时,拓宽学生的知识面,并向不同研究方向的学科组之间提供有效的交流平台。在学术Poster展创新交流活动中参加同学张贴学术海报并讲解相关领域学术成果,同时现场参与及围观的同学进行现场交流。

本次Poster交流大会的地点为科创大厦,共有9篇Poster参加了此次的交流:
1. C2C-GenDA:用于扩充SLOT FILLING数据的Cluster-to-Cluster生成(AAAI 2021)
侯宇泰等人提出了一种全新的Cluster-to-Cluster生成范式来生成新数据,并基于此提出了一个全新的数据增强框架,称为C2C-GenDA。C2C-GenDA通过将现有句子重构为表达方式不同但语义相同的新句子,来扩大训练集。与过往的Data Augmentation(DA)方法逐句(One-by-one)构造新句子的做法不同,C2C-GenDA采用一种多到多(Cluster-to-Cluster)的全新的新语料生成方式。
具体的,C2C-GenDA联合地编码具有相同语义的多个现有句子,并同时解码出多个未见表达方式的新句子。
2. 小样本学习下的多标签分类问题初探(AAAI 2021)
小样本学习(Few-shot Learning)近年来吸引了大量的关注,但是针对多标签问题(Multi-label)的研究还相对较少。在本文中,侯宇泰等人以用户意图检测任务为切入口,研究了的小样本多标签分类问题。对于多标签分类的SOTA方法往往会先估计标签-样本相关性得分,然后使用阈值来选择多个关联的标签。为了在只有几个样本的Few-shot场景下确定合适的阈值,侯宇泰等人首先在数据丰富的多个领域上学习通用阈值设置经验,然后采用一种基于非参数学习的校准(Calibration)将阈值适配到Few-shot的领域上。为了更好地计算标签-样本相关性得分,工作将标签名称嵌入作为表示(Embedding)空间中的锚点,以优化不同类别的表示,使它们在表示空间中更好的彼此分离。在两个数据集上进行的实验表明,所提出的模型在1-shot和5-shot实验均明显优于最强的基线模型(baseline)。
3. 基于反事实推理的开放域生成式对话(EMNLP 2020)
开放域对话系统由于潜在回复数量过大而存在着训练数据不足的问题。朱庆福等人在本文中提出了一种利用反事实推理来探索潜在回复的方法。给定现实中观测到的回复,反事实推理模型会自动推理:如果执行一个现实中未发生的替代策略会得到什么结果?这种后验推理得到的反事实回复相比随机合成的回复质量更高。在对抗训练框架下,使用反事实回复来训练模型将有助于探索潜在回复空间中的高奖励区域。在DailyDialog数据集上的实验结果表明,朱庆福等人的方法显著优于HRED模型和传统的对抗训练方法。
4. 开放域对话系统的属性一致性识别(EMNLP 2020)
一致性问题是当前开放域对话面临的主要问题之一。已有的研究工作主要探索了如何将属性信息融合到对话回复中,但是很少有人研究如何理解、识别对话系统的回复与其预设属性之间的一致性关系。为了研究这一问题,宋皓宇等人构建了一个大规模的人工标注数据集KvPI(Key-value Profile consistency Identification)。该数据集包含了超过11万组的单轮对话及其键值对属性信息,并且对回复和属性信息之间的一致性关系进行了人工标注。在此基础上,工作提出了一个键值对结构信息增强的BERT模型来识别回复的属性一致性。该模型的准确率相较于强基线模型获得了显著的提高。更进一步,宋皓宇等人在两个下游任务上验证了属性一致性识别模型的效果。实验结果表明,属性一致性识别模型有助于提高开放域对话回复的一致性。
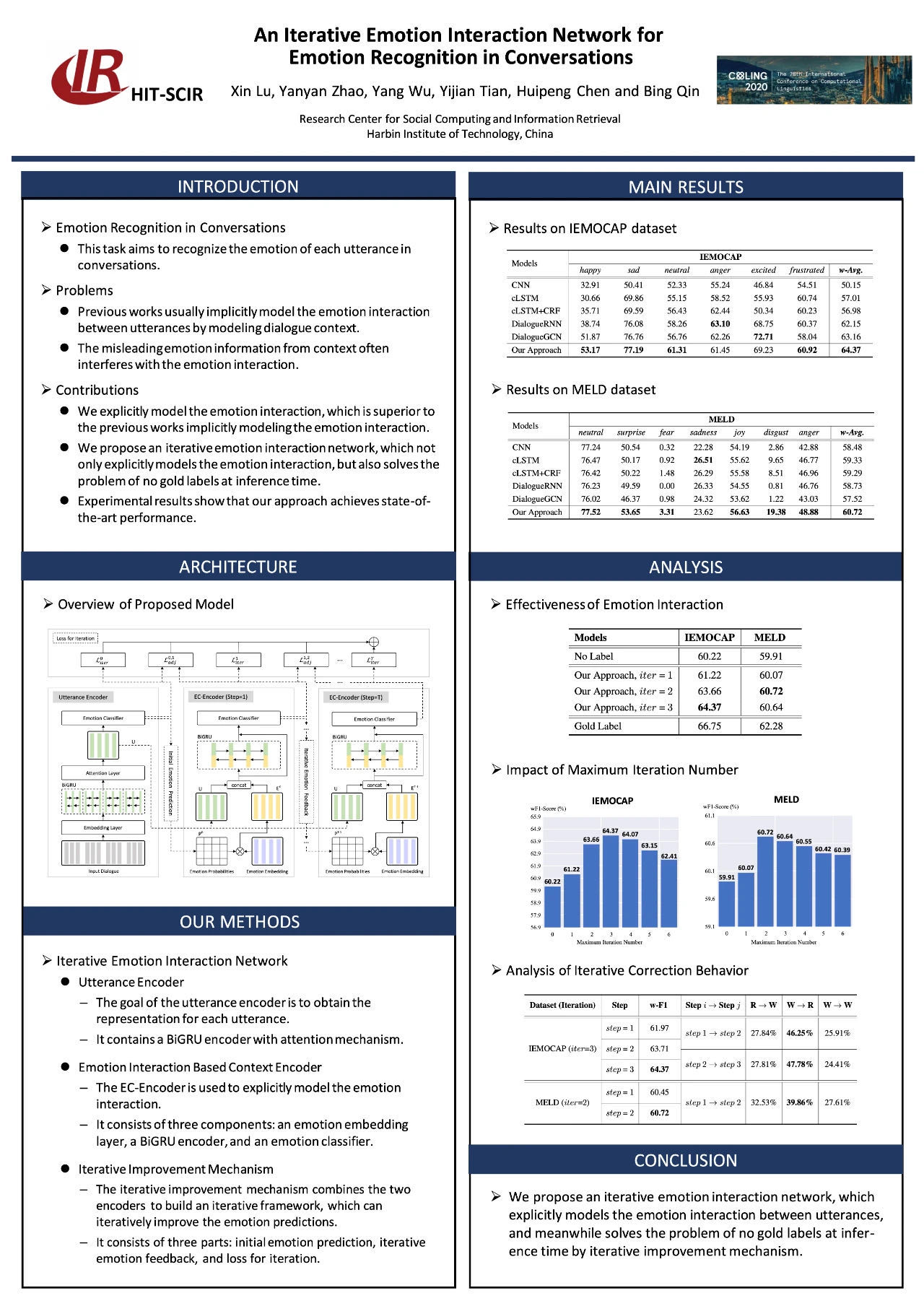
5. 用于会话级情感识别的迭代情感交互网络(COLING 2020)
该任务旨在识别对话中每种说话的情感。之前的工作通常通过对对话上下文进行建模来隐式地对话语之间的情感互动进行建模,但来自情境的误导性情绪信息通常会干扰情绪交互。陆鑫等人显式地对情感交互进行建模,这优于先前的隐式地对情感交互建模的工作。工作提出了一个迭代的情感交互网络,它不仅可以对情感交互进行显式建模,而且可以解决推理时没有金牌的问题。实验结果表明,陆鑫等人的方法达到了最先进的性能。
6. 学习结合语言和符号信息以进行基于表的事实验证(COLING 2020)
基于表的事实验证有望同时执行语言推理和符号推理,例如count,argmax等。现有的事实验证方法侧重于对自然语言的理解,即语言推理,但是没能结合使用语言信息和符号信息。 施琦等人提出了一个基于异构图的神经网络,用于基于表的事实验证,称为HeterTFV,以学习结合两种类型的信息。
7. TableGPT:具有表结构重构和内容匹配功能的小样本表到文本生成(COLING 2020)
表格到文本的生成,旨在生成有关结构化数据中重要信息的描述性文本,在以可理解和自然的方式与人沟通方面具有良好的应用前景,例如财务报告,医疗报告的生成等。龚恒等人使用基于模板的表序列化将结构化表编码为序列,模型将值表示形式的属性名称视为重构的标签,并通过最佳传输来测量文本和表格中信息之间的距离。
8. Molweni:面向多人对话的机器阅读理解与语篇结构分析数据集(COLING 2020)
在本文中,李家琦等人提出了构建于多人对话的英文机器阅读理解(MRC)数据集——Molweni,并覆盖了对话语篇结构。Molweni源自于Ubuntu聊天语料库,包括10,000个对话,共计88,303条话语(utterance)。工作共标注了30,066个问题,包括可回答和不可回答的问题。Molweni独特地为其多人对话提供了语篇结构信息,共标注了78,245个语篇关系实例,为多人对话语篇结构分析(Discourse parsing)贡献了大规模数据。实验表明,Molweni对于现有的MRC模型是一个具有挑战性的数据集;SQuAD 2.0数据集上的强大模型BERT-wwm在Molweni数据集上只取得67.7%的F1值,相比于其在SQuAD 2.0上的表现有20+%的显著下降。
9. “内部知识”的使用:从外部资源中解放出来的生物医学文献搜索(BIBM 2020)
生物医学领域知识通过减少查询和文档之间的语义鸿沟并显着提高BLS系统的性能,在BLS中起着至关重要的作用。
外部知识在知识使用的两个方面受到限制:完整性和时效性。
• 手动和自动构建的BioKB都不完整。
• 大多数最新的BioKB都是为了提供一般和经典的生物医学常识,而这些知识通常不是最新的。
内部知识为可以为BLS系统提供不错的完整性和时效性。
• BLS系统中的大量领域相关文献可提供足够的知识来填补查询文本和候选文档文本之间的语义鸿沟。
•内部知识的更新取决于BLS系统文献的内容,因此,随着BLS系统的不断更新,所使用知识的时效性是有保证的。
此次Poster交流大会从14:00开始到17:00结束,参展的9篇Poster涉及对话、生物医学搜索等多个领域。其间实验室全体师生在科创大厦展览区就参展Poster进行了热烈的讨论,在交流和创新中充实完善了自己的知识体系。