

论文名称:How does Architecture Influence the Base Capabilities of Pre-trained Language Models? A Case Study Based on FFN-Wider and MoE Transformers
论文作者:陆鑫,赵妍妍,秦兵,霍亮宇,杨青,许冬亮
论文会议:NeurIPS 2024
论文链接:https://proceedings.neurips.cc/paper_files/paper/2024/hash/9f2b171fd3f4ca8dd71d1998f65c356a-Abstract-Conference.html
转载须标注出处:哈工大SCIR
1. 简介
基于Transformer架构的MoE大模型具有以低计算成本大幅度提升模型规模的优势,目前已取得了十分瞩目的成果[1-4]。但从MoE大模型兴起的早期阶段到当下,有一个现象始终没有得到良好的解释,即:MoE模型相比稠密模型会出现一定程度的基础能力退化。已有多篇研究工作关注到此问题[1,5-7],但尚无对此现象的合理解释和解决方案。
本工作关注此问题,通过分析定位到问题很可能不存在于MoE层本身,而是位于MoE大模型通常配套使用的标准Transformer架构中。具体而言,原始Transformer中的FFN层,其参数和能力与架构设计匹配,可以与组合函数MHA层形成良好配合;而基于Transformer架构的MoE大模型,其MoE层的参数和能力大幅提升,预训练优化时会自然出现利用残差捷径绕过组合函数MHA层、更多靠MoE层直接完成预训练目标的倾向,从而导致基础能力遭到破坏。
本工作基于以上解释设计了不含残差捷径的新配套架构,并成功在14B参数规模、100B预训练Token下,验证了新配套架构MoE大模型基础能力的显著提升,对于未来架构分析、架构改进和架构设计等方面具有一定的参考意义。
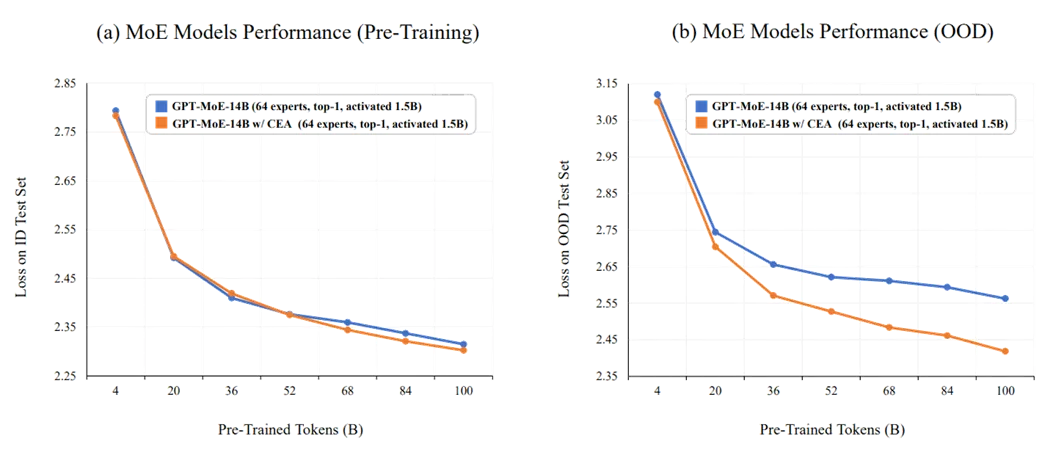
图1:新配套架构MoE模型在预训练性能接近的情况下,实现了分布外泛化能力的显著提升
2. 背景
近年来,大量研究和应用已证明基于Transformer架构的大模型具有强大的基础能力,并具有随规模增大而基础能力不断提升的重要特性。然而,增大模型规模在实际应用中代价很高,因为这往往伴随着运算量的快速增长。因此,相关工作逐渐将目光转移到了混合专家模型(MoE)上,这是一种动态神经网络模型,允许不同输入被不同专家处理,专家数量直接决定了模型参数量但却又对实际运算量影响有限,因而具有以低运算代价高效扩展模型容量的优越特性。
大模型中应用MoE的做法,通常是将Transformer中的FFN层替换为MoE层,然后Transformer中的其他模块、数据流动方式等基本保持不变。例如,早期的Switch Transformers工作在其论文中通过图示直接展示了这一点[1]。而后的MoE大模型基本沿用了类似做法,相关改进也通常集中于MoE层内部,少量工作会修改其他模块,但一般也会保持架构中的数据流动方式不变。
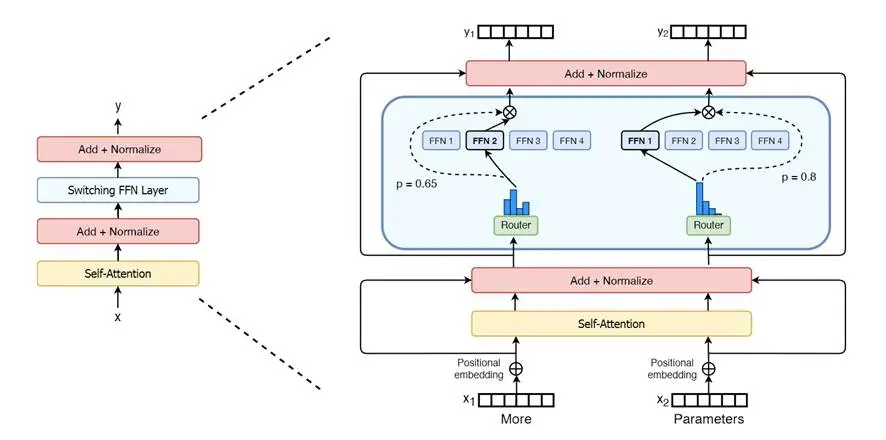
图2:Switch Transformers采用直接将FFN层替换为MoE层的做法[1],相关工作大多也采取类似做法
然而,Switch Transformers工作也发现一个MoE模型的负面现象[1],即:MoE模型虽然可以很好地完成预训练语言建模任务,但达到相同预训练水平时MoE模型的基础能力往往不如稠密模型。例如,Switch Transformers工作在其论文中就明确指出,MoE模型并未很好地将预训练性能转化为下游SuperGLUE任务性能。
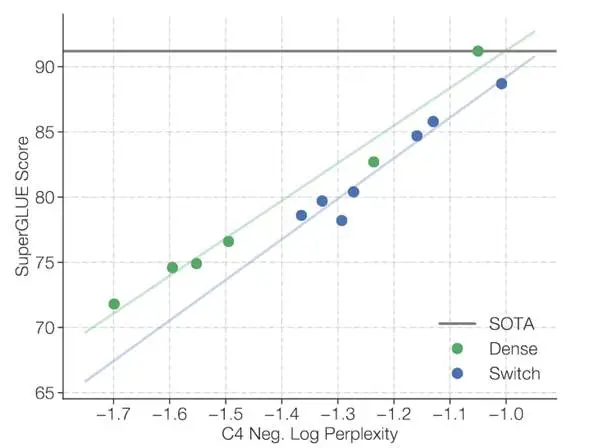
图3:Switch Transformers论文中展示MoE模型在将预训练性能转化为下游SuperGLUE性能时,相比稠密模型出现明显退化[1]
此问题后续也被其他工作观察到[1,5-7],也有工作尝试从过拟合等角度进行解释[6],但一直没有特别好的结果。本工作关注此问题,尝试给出合理的解释和有效的解决方案。
3. 分析与方法
3.1 从MoE层到宽FFN层
本工作首先观察到,虽然不同工作都发现了MoE模型基础能力退化的现象,但是它们具体使用的MoE层并不完全相同,甚至部分机制存在明显差异。但从一致性的角度看,它们都具有参数规模大幅度增长的共同特点。这引发了一个初步的猜测:基础能力退化可能与MoE层(或FFN层)的具体实现无关,而是与参数规模和能力相关。
为了验证这个想法,我们对标准Transformer进行简单变化,仅将原始FFN层中的隐层维度倍数从4倍扩大到32倍,然后预训练多种规模的标准BERT/GPT模型和宽FFN层BERT/GPT模型,对比在预训练性能相同时它们在分布外语言建模、少样本学习、下游迁移微调上的性能情况,具体如下图所示。
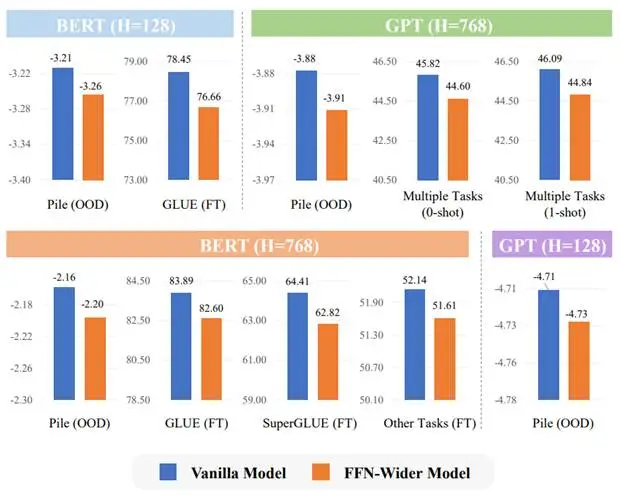
图4:预训练性能相同时,标准Transformer与宽FFN层Transformer性能对比
实验结果显示,具有更宽FFN层的模型出现了明显的基础能力退化,这与MoE模型的现象是类似的,大体证实了我们的猜测。因此,我们可以基于更易训练和调整的宽FFN层模型进行更深入的分析,以寻求更具体的原因解释和启发解决方案。
3.2 组合函数与变换函数
基于上面结果,我们可以将怀疑目标从FFN层(或MoE层)的具体实现中解脱出来,而对Transformer中抽象的组件和结构进行分析。具体而言,除去输入输出嵌入层等,Transformer中主要包含两个组件:组合函数MHA层和变换函数FFN层,具体如下图所示。
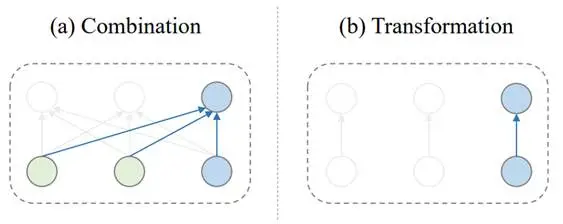
图5:Transformer中的组合函数(MHA)与变换函数(FFN)
从图中不难看出,考虑序列中某一个位置,这个位置通过MHA层后得到的更新表示,是由序列上下文组合而来的;而这个位置通过FFN层后得到的更新表示,是仅由这个位置的表示经过上下文无关的独立变换得来的。
考虑只由一层MHA或一层FFN构成的模型,我们发现实际上它们都可以用于处理语言建模任务,如果当成黑盒只看输入输出是没有分别的,但是它们完成语言建模的方式是截然不同的:FFN是把上一个Token直接映射成目标Token,是一种一对一的变换函数;而MHA则是利用了序列上下文去计算得到目标Token,是一种多对一的组合函数。不难感觉到,其中后者是与组合性等先验更加暗中契合的。
再考虑由MHA层和FFN层多层堆叠的Transformer模型,我们又很容易得到这样的认识:虽然所有层都在为完成最终的语言建模目标做贡献,但它们是以不同的归纳偏置进行着的,而这其中的MHA层可能是模型架构表达组合性等先验的集中体现。
基于这样的认识,当我们再审视FFN层变宽或容量增大时,一个十分自然的想法是:是不是这种变化会导致FFN层这种变换函数整体对预训练语言建模的独立贡献比例增大,而间接使MHA层这种组合函数整体对预训练语言建模的贡献比例变小?进而影响了模型架构对于组合性等先验的表达,最终导致了模型基础能力的下降?
而这种FFN层(或MoE层)独立贡献比例可以增大的根源,在于Transformer架构中的残差连接。具体如下图所示,架构中存在可以绕过组合函数MHA层的残差通路,这给图中MoE层独立贡献提供了支持。
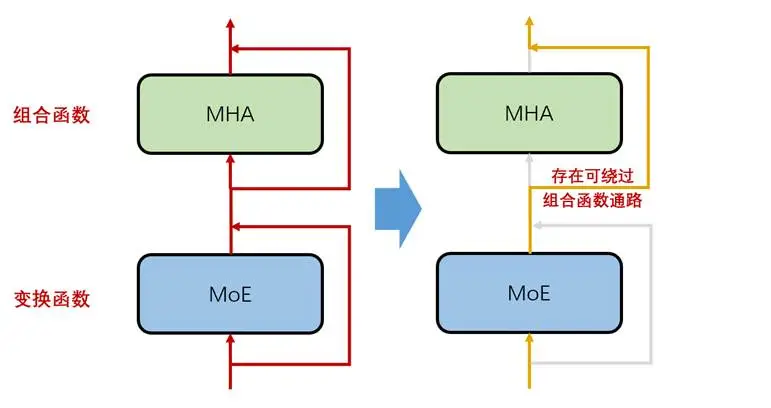
图6:Transformer存在可允许MoE层独立贡献的残差通路
因此我们猜测:MHA层这种组合函数对预训练语言建模的贡献比例是影响模型基础能力的关键因素。宽FFN模型、MoE模型等基础能力变差,源于宽FFN层、MoE层独立贡献比例的升高,进而导致的MHA层实际贡献比例下降。
验证我们的猜想需要从两个方面进行:
第一,验证在宽FFN模型中,MHA组合函数对预训练语言建模的贡献比例是否真的降低。
第二,修改宽FFN模型架构,使其可以自由地调节MHA组合函数的贡献比例,验证模型基础能力是否会随MHA贡献比例的升高而升高。
3.3 贡献分析
我们设计了两种贡献分析方法:基于互信息的方法和基于Token预测的方法。
第一种分析方法是互信息方法。它的基本思想是这样的:对于序列中需要输出预测Token的位置,我们可以关注这些位置经过每一个层后的表示,计算这些表示与目标Token的互信息,就会得到一个大体上单调递增的互信息序列,最后一个互信息值减去第一个互信息值就是经过所有MHA层和FFN层后的互信息总增长量。然后,由于我们有经过任意一层之前和之后的互信息值,我们就可以分别计算MHA层和FFN层各自的贡献比例,也就达成了我们的目的。具体结果如下图所示。
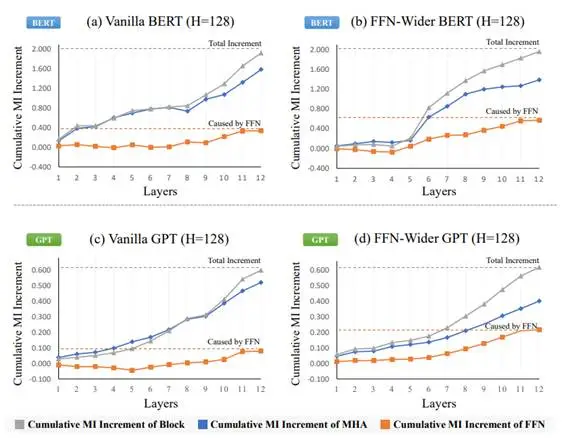
图7:基于互信息的贡献分析结果
从结果中可以看出,宽FFN模型中FFN层的互信息贡献要明显高于标准模型中FFN层的互信息贡献,无论对于BERT还是GPT都是如此,这初步验证了我们的猜测。
第二种分析方法是Token预测方法。由于互信息方法需要对大量表示进行聚类,在隐层维度高的时候开销很大,因此我们又尝试了另一种更直接的方法,即直接从中间层表示预测出Token,可以获得一个大体上单调递增的预测准确率序列,然后采用类似的方法计算MHA层和FFN层各自的贡献比例。具体结果如下图所示。

图8:基于Token预测的贡献分析结果
Token预测分析结果与互信息分析结果类似,宽FFN模型中FFN层的贡献要明显高于标准模型中FFN层的贡献,同样初步验证了我们的猜测。
3.4 组合调节架构与趋势分析
虽然我们观察到了宽FFN模型中FFN层的实际贡献更大,但仍不能断言这是模型基础能力变差的原因,因为这可能只是一种相关关系,而非模型基础能力的决定性因素。
因此,我们设计了一种能直接干预MHA组合函数贡献的新架构,名为组合调节架构。一方面可以通过观察基础能力变化情况直接证实它是否为决定性因素,另一方面能切实改善宽FFN模型的基础能力。
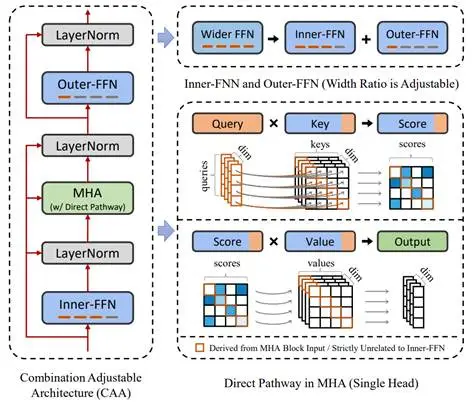
图9:组合调节架构示意图
我们设计的组合调节架构如上图所示,它相比于原始宽FFN模型有两个变化:一个是把之前完全在MHA外部的FFN,部分转移到MHA内部成为Inner-FFN;另一个则是在MHA内部添加了不经过Inner-FFN的直接通路。
其中,前者的设计思想完全继承于前面分析,通过对数据流动方式的重新设计,迫使Inner-FFN无法绕过MHA进行独立贡献。后者是更具体的补充,由于MHA中对本位置的加权求和仍会导致捷径通路的存在,因此让本位置的信息全部来源于Inner-FFN变换之前。
组合调节架构中,Inner-FFN和Outer-FFN的总宽度固定,两者的宽度比例可以自由调节,我们尝试调节多种比例关系并预训练多组模型,绘制Outer-FFN贡献比例趋势和分布外语言建模性能趋势,具体如下图所示。
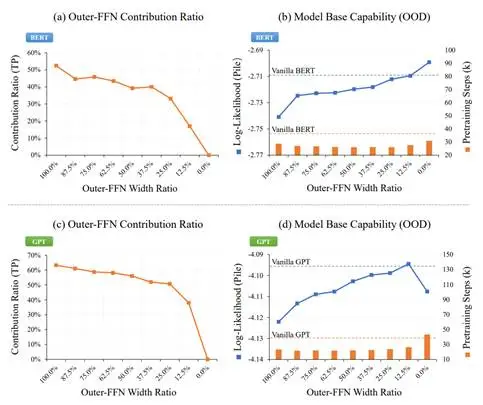
图10:不同宽度比例下Outer-FFN贡献比例趋势和分布外语言建模性能趋势
从图中不难看出,Outer-FFN的贡献比例确实会随着Outer-FFN宽度比例的不断降低而降低,同时意味着MHA和MHA内部Inner-FFN的贡献比例在不断升高;同时,模型分布外语言建模的性能也确实会随着Outer-FFN宽度比例的不断降低而升高(图中唯一异常点的深层次原因详见论文附录G)。
因此组合上述现象后,我们基本验证了我们的猜测:模型基础能力大体上是会随着组合函数实际贡献比例的不断升高而升高。宽FFN模型、MoE模型等基础能力变差,源于其参数和能力增强后通过残差捷径做出的独立变换贡献,间接导致了组合函数贡献比例降低。
此外,前面提出的组合调节架构可转化为我们的最终架构,通过将组合调节架构的宽度比例固定为常数值,即可成为最终的新架构—组合增强架构。
4. 实验
本工作包含对小规模宽FFN模型的实验和对大规模MoE模型的实验,我们将主要介绍相对更重要的MoE模型相关实验。
首先,我们选择了一个1.3B的GPT模型作为主干模型,该模型在GPT架构基础上添加了RoPE和RMS Norm。然后,在此结构基础上,我们在FFN层前面又添加了一个64专家Top-1激活的MoE层,得到具有14B参数的MoE基线模型。最后,我们带有组合增强架构的改进版本,是将整个MoE层变为在MHA内部的Inner-MoE层,原有FFN层保持不变作为Outer-FFN层。为了可以适配FlashAttention-V2[8],我们对MHA中的直接通路做了简化(即图9右侧部分),没有通过替换本位置的Key和Value来防止变换泄露,而是选择直接将本位置Mask来达到相同的目的。
然后,我们选择在SlimPajama数据集[9]中的CC和C4子集合上进行预训练,对3个模型都从头训练了100B Token。由于SlimPajama数据集实现了跨子集合的去重,所以我们将其中的其他领域集合数据作为分布外测试集。我们进行了全面的分布外语言建模测试和少样本学习测试,结果如下表所示。

表1:稠密模型、基线MoE模型和改进MoE模型的性能对比,其中†代表与预训练数据同分布的语言建模测试集
从结果中不难看出,我们的新架构十分显著地提升了MoE模型在分布外语言建模和少样本学习上的性能,这充分证明了我们分析和改进方法的有效性。
5. 总结
本工作主要关注基于Transformer架构的MoE模型所表现出的基础能力退化问题,通过分析定位到问题不在MoE层本身,而是位于MoE模型通常配套使用的标准Transformer架构中。我们指出大参数量的强MoE层会利用残差捷径绕过组合函数MHA层直接服务于预训练目标,从而导致基础能力遭到破坏。我们据此设计了不含残差捷径的新配套架构,并成功在14B参数规模、100B预训练Token下,验证了新配套架构MoE大模型基础能力的显著提升,对未来工作具有一定的参考意义。
参考文献
[1]Fedus W, Zoph B, Shazeer N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity[J]. Journal of Machine Learning Research, 2022, 23(120): 1-39.
[2]Dai D, Deng C, Zhao C, et al. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models[J]. arXiv preprint arXiv:2401.06066, 2024.
[3]Liu A, Feng B, Wang B, et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model[J]. arXiv preprint arXiv:2405.04434, 2024.
[4]Liu A, Feng B, Xue B, et al. Deepseek-v3 technical report[J]. arXiv preprint arXiv:2412.19437, 2024.
[5]Artetxe M, Bhosale S, Goyal N, et al. Efficient large scale language modeling with mixtures of experts[J]. arXiv preprint arXiv:2112.10684, 2021.
[6]Zoph B, Bello I, Kumar S, et al. St-moe: Designing stable and transferable sparse expert models[J]. arXiv preprint arXiv:2202.08906, 2022.
[7]Shen S, Hou L, Zhou Y, et al. Mixture-of-experts meets instruction tuning: A winning combination for large language models[J]. arXiv preprint arXiv:2305.14705, 2023.
[8]Dao T. Flashattention-2: Faster attention with better parallelism and work partitioning[J]. arXiv preprint arXiv:2307.08691, 2023.
[9]Shen Z, Tao T, Ma L, et al. Slimpajama-dc: Understanding data combinations for llm training[J]. arXiv preprint arXiv:2309.10818, 2023.