

论文名称:TEA-Bench: A Systematic Benchmarking of Tool-enhanced Emotional Support Dialogue Agent
论文作者:隋星宇,赵妍妍,胡雨林,郭家合,赵伟翔,秦兵
论文链接:https://arxiv.org/pdf/2601.18700
数据链接:https://huggingface.co/datasets/XingYuSSS/TEA-Dialog
代码链接:https://github.com/XingYuSSS/TEA-Bench
转载须标注出处:哈工大SCIR
告别空泛安慰,开启实用陪伴。作为首个面向工具增强情绪支持对话的系统评测基准,TEA-Bench推动AI从“会说漂亮话”迈向“提供真帮助”,让情感支持既有温度,更有现实依据。
1.工具增强情绪支持对话研究背景
告别空泛安慰,开启实用陪伴。
当用户说“我今天很累,不想直接回家”时,一个真正有帮助的 AI 不应只回答“你辛苦了”,还应意识到他可能需要一个附近安静、适合放松的去处;当用户说“我加班到崩溃”时,模型也不能在不知道当前时间的情况下,就轻率地劝他“早点休息”。情绪支持并不只是说几句温柔的话,更重要的是能否结合用户所处的现实情境,提供具体、可靠、可执行的帮助。
近年来,大语言模型在开放域对话、角色扮演和情绪支持等任务中展现出越来越强的语言生成能力。面对焦虑、疲惫、孤独或压力等情绪表达,模型已经能够生成较为自然的回应,例如表达理解、提供安慰、给予鼓励,或建议用户进行休息和情绪调节。这推动了情绪支持对话的发展,也让“有温度的 AI 陪伴”成为人机交互中的重要方向。
然而,真实世界中的情绪困扰往往并不是孤立存在的,而是与具体时间、地点、天气、环境、事件背景和可用资源密切相关。用户需要的也不一定只是情绪上的安慰,还可能是现实中的支持:附近是否有安静空间?现在是否适合外出?有没有可以联系的服务资源?某个建议是否符合当前处境?如果模型缺乏外部信息支撑,却仍然给出看似具体的建议,就很容易产生事实错误,甚至造成误导。
这也暴露出现有情绪支持对话系统的一个关键不足:很多系统仍停留在“会说漂亮话”的层面,主要关注模型是否能够识别情绪、表达共情、提供安慰和鼓励,却较少考察模型能否提供真正可落地的 instrumental support。与 affective support 所强调的情绪理解和情感回应不同,instrumental support 更关注具体、可执行、与现实处境相关的帮助。它往往需要时间、位置、天气、地图、搜索、百科或社区经验等外部信息作为 grounding,否则模型很容易生成温柔但空泛、具体但不可靠的回复。
更进一步看,这一问题也反映了情感陪伴边界的拓展。过去的情感陪伴更多是对话式陪伴:模型通过语言理解用户情绪、表达共情、提供安慰,并在交流中建立陪伴感。但随着大语言模型向智能体形态发展,情感陪伴正在从“会回应”走向“能行动”,从单纯的文本交互走向面向真实处境的智能体式陪伴。未来的 AI 陪伴不应只是被动聊天,而应能够感知情境、识别需求、调用工具,并将外部信息转化为有现实依据的支持。
工具增强大模型为这一方向提供了新的可能。通过调用搜索、地图、天气、时间、百科、社区经验等工具,模型可以在对话过程中动态获取外部信息,从而减少凭空猜测,并为用户提供更具体、更可靠的帮助。但情绪支持场景中的工具使用并不像传统工具调用任务那样明确。用户往往不会直接说“请你调用工具”,也不会给出清晰的 API 目标。模型必须自行判断:当前回复是否存在信息缺口?是否需要外部工具?应该调用什么工具?工具结果是否可靠?又该如何把这些结果转化为既有情感温度、又符合现实情境的支持性表达?
基于这一问题,我们提出 TEA-Bench(Tool-enhanced Emotional Support Dialogue Agent Benchmark),作为首个面向工具增强情绪支持对话智能体的系统评测基准。TEA-Bench 的目标不是简单地给情绪支持模型“接入工具”,而是系统评估工具在情绪支持对话中的真实作用:工具是否能够提升支持质量?是否能够减少幻觉?不同能力层级的模型是否都能从工具中受益?模型在多轮情绪支持中究竟如何识别信息需求、调用工具并整合外部信息?
TEA-Bench 希望推动情感陪伴从“会说漂亮话”的对话式陪伴,迈向“能提供真帮助”的智能体式陪伴。在这一框架下,一个优秀的情绪支持智能体不仅要能表达理解和关心,还要能在必要时主动获取现实信息,避免无依据的建议,提供更具体、更可靠、更贴近用户处境的支持。换言之,情感支持不应止于安慰,而应既有温度,更有现实依据。
这一点在情绪支持场景中尤为重要。相比普通问答,情绪支持中的幻觉具有更高风险。用户在情绪低落、压力较大或处于脆弱状态时,可能更容易相信模型给出的具体建议。如果模型虚构附近资源、错误判断当前时间、随意推荐并不存在的地点,或在缺少事实依据时给出过于具体的生活建议,都可能削弱用户信任,甚至带来潜在风险。因此,情绪支持智能体的可靠性不能只通过“回复是否温暖”来衡量,还必须考察其事实 grounding、工具使用能力和幻觉控制能力。
TEA-Bench 正是为此而来:让 AI 情感陪伴告别空泛安慰,走向有温度、有依据、有行动价值的实用陪伴。

图1:仅依赖情感表达的回复与工具增强回复的对比
2.TEA-Bench 交互式基准评测框架
TEA-Bench 的核心并不是简单地给情绪支持模型接入工具,而是评估模型在真实多轮对话中能否完成一套更复杂的决策过程:先理解用户情绪,再判断当前回复是否需要外部信息,如果需要,再调用合适工具获取事实,最后把工具结果自然地融入支持性回复中。
这使得 TEA-Bench 与传统情绪支持对话和传统工具调用任务都不一样。与传统情绪支持任务相比,TEA-Bench 更强调事实 grounding。模型不能只生成温柔的话,还要避免在没有依据的情况下给出具体建议。与传统工具调用任务相比,TEA-Bench 又更强调开放式交互。用户不会明确告诉模型“调用哪个工具”,也不会给出清晰的 API 目标。模型必须自己判断什么时候该倾听,什么时候该查证,什么时候该建议,什么时候该保持不确定。
因此,TEA-Bench 实际上评估的是一种复合能力:情绪理解、工具规划、事实获取、信息整合和风险控制。模型既要避免空泛安慰,也要避免工具滥用;既要提供具体支持,也要避免把不确定信息说成确定事实。这使得工具增强情绪支持对话成为一个更接近真实复杂交互的智能体评测问题。
为系统研究这一问题,TEA-Bench 构建了面向情绪支持对话的交互式评测框架。该框架包含情绪支持场景、工具环境、用户模拟器以及过程级评估指标。与静态问答式评测不同,TEA-Bench 强调多轮交互中的行为过程,即模型不只是生成一次回复,而是在持续对话中不断理解用户状态、决定是否调用工具,并根据用户反馈调整后续回复。
在场景构建上,TEA-Bench 关注具有现实感的情绪困扰情境。这些场景覆盖不同的情绪来源和支持需求,例如工作压力、社交困扰、孤独感、生活安排、健康焦虑或现实决策等。它们共同的特点是,用户表面上表达的是情绪,但背后可能隐藏着需要外部信息支持的现实问题。因此,模型不能简单按照固定情绪支持模板生成回复,而需要根据对话进展判断具体需求。
在工具环境上,TEA-Bench 使用 MCP-style 的工具环境,使模型能够访问不同类型的外部信息。这些工具并不是为了完成某个确定任务而存在,而是为情绪支持提供 grounding。例如,时间工具可以帮助模型避免错误假设当前时间;位置与地图工具可以帮助模型提出更贴近用户处境的建议;天气工具可以帮助模型判断户外活动是否合适;百科和搜索类工具可以辅助模型获取背景知识。工具的价值不在于替代情绪支持,而在于让支持性建议更可信、更具体。
在评估方式上,TEA-Bench 不只考察最终回复质量,还关注过程级行为。一个模型可能最终生成了看似温柔的回复,但如果其中包含无依据的事实假设,就不能被视为可靠支持;另一个模型可能调用了多个工具,但如果工具结果没有被合理整合,或者回复变得生硬,也不能说明它具备优秀的工具增强能力。因此,TEA-Bench 同时评估情绪支持质量和事实 grounding,使模型表现能够从“会不会安慰”扩展到“是否可信地安慰”。
这种评估设定的意义在于,它将情绪支持对话从单纯的文本生成问题,推进到更完整的人机交互问题。模型需要在开放式对话中持续做决策,而不是完成一个预先写明的工具调用脚本。也正因如此,TEA-Bench 能够揭示不同模型在工具使用策略上的差异:有些模型能够选择性地调用工具,有些模型会过度调用工具,有些模型即使接入工具也难以真正受益。

图2:工具增强情绪支持对话示例

图3:TEA-Bench 的评测框架
3.关键发现:工具有用,但关键在于会不会用
从实验结果看,工具增强总体上能够提升情绪支持质量,并减少幻觉。这说明,在情绪支持对话中引入外部信息并不是一个可有可无的附加功能,而是提高可靠性的关键手段。
当模型能够调用工具时,它不必凭空猜测当前时间、天气、位置或背景知识,而可以通过工具获得事实依据。这样生成的建议就不再完全依赖语言模式,而是建立在更可验证的信息之上。对于情绪支持场景来说,这一点尤其重要,因为用户在焦虑、疲惫或脆弱状态下,往往更需要具体、现实、可执行的帮助。
但实验也说明,工具不是万能补丁。强模型能够更好地判断何时需要工具,并把工具结果自然整合到回复中;中等模型也能从工具中获益,但往往需要更多调用才能达到相近的 grounding 效果;弱模型即使接入工具,收益也比较有限,因为它们可能不知道什么时候该调用工具,也可能无法正确理解工具结果。
因此,工具增强更像是一种能力放大器。它能放大模型原有的理解、规划和整合能力,但不能自动弥补这些能力的缺失。工具增强情绪支持的关键不在于“是否接入工具”,而在于模型是否具备合理使用工具的能力。
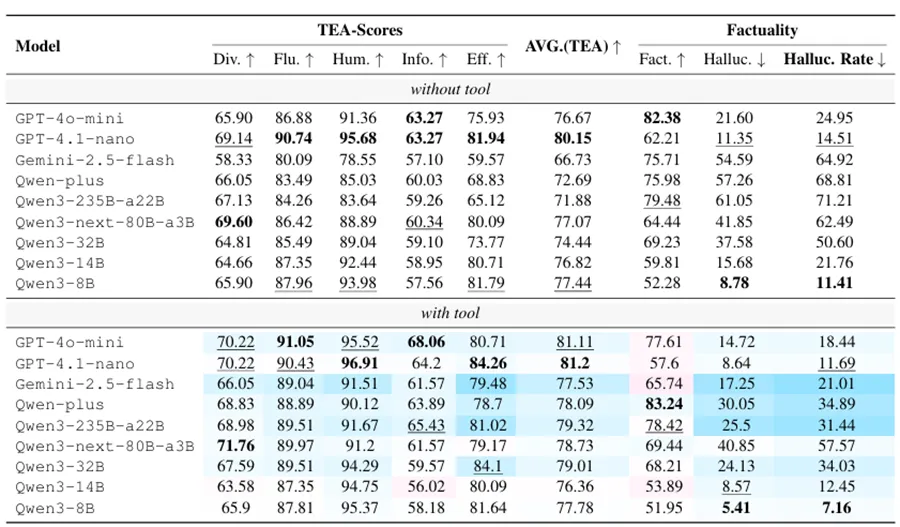
图4:不同能力模型在工具增强情绪支持中的表现差异
4.分析:TEA-Bench 为什么值得关注?
TEA-Bench 的价值不只是提出了一个新 benchmark,更重要的是它改变了我们理解情绪支持智能体的方式。过去评价情绪支持模型时,我们常常关注回复是否温暖、是否共情、是否能安慰用户。但 TEA-Bench 提醒我们,在真实应用中,“温暖”并不等于“可靠”。一个回复可能语气很好,却包含没有依据的事实假设;也可能表达很关心,却给出了错误的地点、时间或资源建议。
这也是情绪支持场景区别于普通问答的地方。用户在情绪低落或压力较大时,可能更容易相信模型的建议。如果模型为了显得体贴而编造具体细节,风险反而更高。因此,情绪支持智能体的可靠性不能只通过“回复是否温暖”来衡量,还必须考察其事实 grounding、工具使用能力和幻觉控制能力。
从这个角度看,工具调用在 TEA-Bench 中并不是为了完成某个外部任务,而是作为一种事实 grounding 机制。它帮助模型减少错误假设,让支持性回复更贴近现实处境。
不过,TEA-Bench 也揭示了一个更难的问题:工具使用必须保持克制。过少的工具调用可能导致幻觉,过多的工具调用则可能破坏对话的自然性和陪伴感。真正理想的模型不是频繁调用工具,而是能够在情绪支持过程中精准判断工具是否必要,并让工具结果服务于支持本身。
5.TEA-Dialog 与后续启发
除 TEA-Bench 外,论文还构建了 TEA-Dialog,用于支持工具增强情绪支持对话的训练与研究。TEA-Dialog 来源于 TEA-Bench 交互过程,包含 grounded、tool-enhanced 的情绪支持对话,为后续模型训练提供了数据基础。
实验表明,使用 TEA-Dialog 进行监督微调可以提升模型在分布内场景中的表现。也就是说,当测试场景与训练数据较为接近时,模型可以学习到更合适的工具使用模式和支持表达方式。这说明,高质量的工具增强情绪支持数据确实有助于改进模型行为。
但模型在分布外场景中的泛化仍然有限,甚至可能在新的场景中重新出现幻觉问题。这一点很关键:它说明工具增强情绪支持并不是简单依靠 SFT 就能解决的问题。模型不能只是记住“某类情绪对应某类工具”或“某类场景对应某类回复”,而需要真正理解当前对话中的信息缺口、用户需求和风险边界。
换句话说,这更像是一个 agent 能力问题,而不仅是一个数据拟合问题。未来如果要构建更可靠的情绪支持智能体,可能需要进一步研究工具使用训练、过程监督、偏好优化、风险感知评估,以及高风险情绪场景下的人类支持机制。
6.总结
总体来看,TEA-Bench 提出了一个值得关注的新问题:情绪支持智能体能否在开放式多轮对话中合理使用外部工具,提供既有情感温度、又有事实依据的帮助。与传统情绪支持任务相比,该问题更强调现实 grounding;与传统工具调用任务相比,该问题更强调情绪理解和开放式交互。
它的意义在于,把情绪支持从“会不会安慰”推进到“是否可信地支持”。好的情绪支持 AI 不应该只是说出温柔的话,还应该在需要时查清事实,在不确定时保持诚实,在给出建议时尊重现实边界。
也就是说,未来的情绪支持智能体既需要共情能力,也需要 grounding 能力;既要有温度,也要有依据。