

声明:本文转载自开放知识图谱公众号

论文链接:https://arxiv.org/abs/2412.11694
仓库链接:https://github.com/threegold116/Awesome-Omni-MLLMs
1. 引言
不断发展的多模态大语言模型(MLLMs)展现了实现通用人工智能的潜力,其通过将大语言模型与特定模态的预训练模型结合,扩展了单一非语言模态的理解与生成能力,例如视觉MLLMs、音频MLLMs和3D-MLLMs。然而,这些特定模态MLLMs(Specific-MLLMs)难以应对现实场景中涉及多模态的复杂任务,因此研究者正致力于扩展模态范围,推动全模态MLLMs(Omni-MLLMs)的发展。为了应对现实场景中的复杂任务,越来越多的研究者将目光投向了全模态大语言模型(Omni-MLLMs),其旨在实现全模态的理解与生成。
Omni-MLLMs通过整合多种非语言模态的预训练模型,在Specific-MLLMs的基础上扩展了理解和生成能力。其利用大语言模型的涌现能力,将不同非语言模态视为不同“外语”,在统一空间内实现跨模态信息的交互与理解。与Specific-MLLMs相比,Omni-MLLMs不仅能执行多种单模态理解和生成任务,还能处理涉及两种或以上非语言模态的跨模态任务,使单一模型能够处理任意模态组合(这里的单模态和跨模态指参与交互的非语言模态数量)。
哈工大社会计算与交互机器人研究中心知识挖掘组(秦兵教授和刘铭教授带领)系统地梳理了相关研究,并对Omni-MLLMs进行了全面的调查。具体而言,我们首先通过细致的分类体系,阐释了Omni-MLLMs实现统一多模态建模的四个核心组成部分,为读者提供了新颖的视角。接着,我们介绍了通过两阶段训练实现的有效整合,并讨论了相关数据集及评估方法。此外,我们总结了当前Omni-MLLMs面临的主要挑战,并展望了未来发展方向。我们希望本文能为初学者提供入门指引,并推动相关研究的进一步发展。
2. Omni-MLLMs分类

3. Omni-MLLMs结构
作为特定模态大语言模型(Specific-MLLMs)的扩展,全模态大语言模型(Omni-MLLMs)继承了编码、对齐、交互和生成的架构,并进一步拓宽了所涉及的非语言模态类型。
3.1多模态编码
3.1.1连续编码
连续编码是指将模态编码到连续特征空间中。采用连续编码的Omni-MLLMs通常整合多个预训练的单模态编码器,将不同模态编码到各自的特征空间,或通过预对齐编码器将多模态统一编码到同一特征空间。
优缺点:连续编码能保留更多的原始特征信息,但不同异构模态编码特征需要复杂的对齐结构进行对齐。
3.1.2离散编码
离散是指将模态编码到离散特征空间中。采用离散编码的Omni-MLLMs通常整合多个离散编特定模态的标记器将模态数据转换为离散标记,从而实现多模态的离散统一表示。
优缺点:离散编码便于模态的统一处理和生成,但离散编码会丢失大量细节信息。
3.1.3混合编码
一些Omni-MLLMs结合离散与连续编码方法,针对不同模态选择最优编码策略,以兼顾模态统一处理与细节信息保留。
3.2多模态对齐
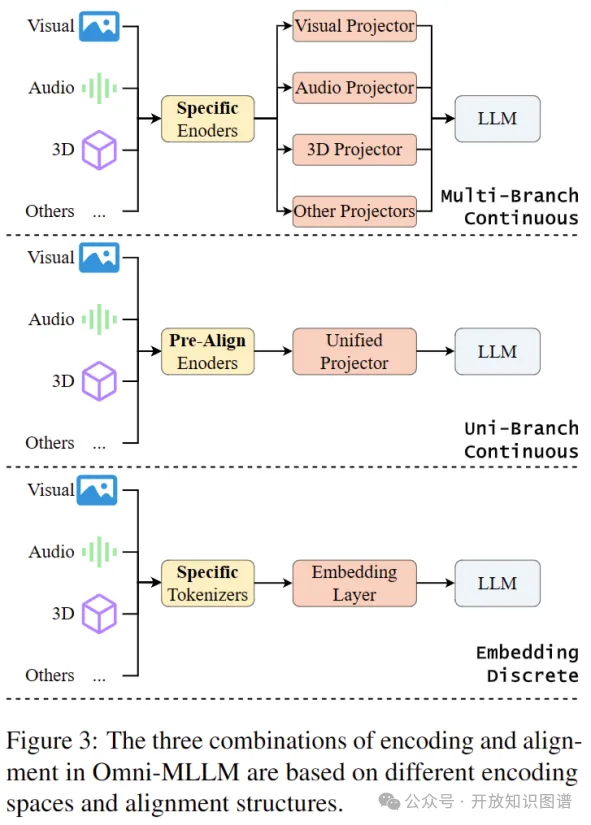
3.2.1投影对齐
连续编码的Omni-MLLMs在编码器与大语言模型之间插入适配器(称为投影器),将连续编码的模态特征映射到文本嵌入空间中。对于处于特异特征空间的模态,通常采用多分支投影(multi-branch),通过多个投影器分别将各模态特征对齐到文本嵌入空间,以解决维度不匹配和特征错位问题。
对于提前对齐处于同一特征空间的多个模态,除了多分支投影外,Omni-MLLMs也可以采用共享投影器实现多模态的统一对齐,以减少多投影器的参数量,这种方法称为单分支投影(uni-branch)。
投影器的实现方式多样,包括MLP、线性层、基于注意力的方法(如Q-Former和Perceiver)以及结合CNN的特征压缩方法。多分支Omni-MLLMs可能针对不同模态采用不同的投影器实现。
3.2.2嵌入对齐
离散编码的Omni-MLLMs通过扩展大语言模型的词汇表和嵌入层,将非语言模态的离散标记嵌入到语言模型的连续特征空间中,实现模态对齐。而部分工作也会通过复写词汇表中的部分低频词以实现对齐。混合编码模型则同时采用投影方法和嵌入方法,以结合两种编码策略的优势。
3.3多模态交互
大多数Omni-MLLMs在输入层将对齐的非语言模态特征与文本特征拼接,实现逐层交互,而部分工作则将模态特征插入大语言模型的特定层或所有层,以减少原始模态信息损失。
在交互涉及的模态数量方面,与Specific-MLLMs仅限于单一非语言模态与文本的双模态交互不同,Omni-MLLMs不仅支持多种双模态交互(dual-modality交互),还能实现涉及两种以上非语言模态的全模态交互(omni-modality交互),展现了Omni-MLLMs处理任意模态组合的能力。
3.4多模态生成
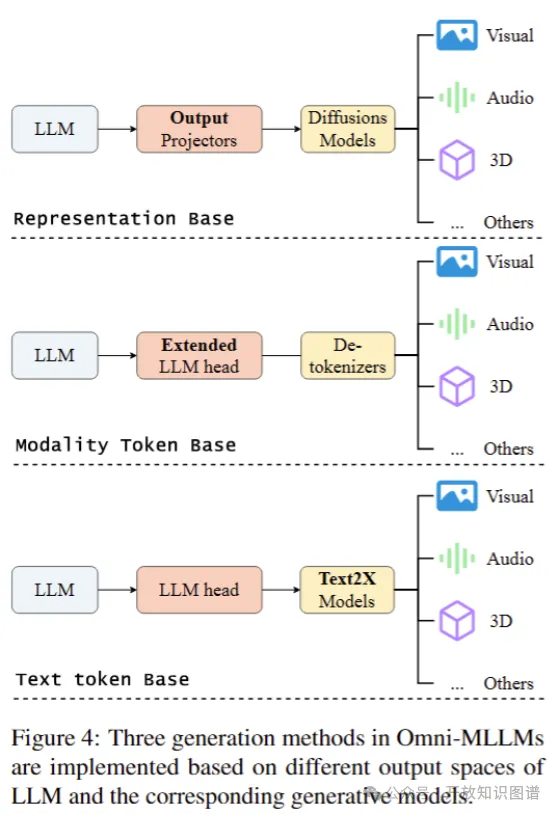
Omni-MLLMs通过整合不同生成模型,不仅能输出文本,还能生成非语言模态。
·基于文本的生成方法直接利用大语言模型的文本输出调用Text-to-X生成模型;
·基于模态标记的生成方法通过扩展大语言模型头部生成模态特定的离散标记,再通过解码器生成多模态内容;
·基于表示的生成方法则通过信号标记将表示映射到多模态解码器可理解的表示,以缓解离散标记引入的噪声。
4.Omni-MLLMs训练
为实现不同向量空间的对齐并提升任意模态设置下的指令跟随能力,Omni-MLLMs扩展了特定模态大语言模型(Specific-MLLMs)的标准两阶段训练流程:多模态对齐预训练和多模态指令微调。
4.1多模态对齐预训练
多模态对齐预训练包括编码端的输入对齐和解码端的输出对齐。输入对齐训练不同模态特征空间与大语言模型嵌入空间的对齐,而输出对齐训练嵌入空间与各模态解码器输入空间的对齐。输入对齐和输出对齐可以分别进行,也可以同时进行。
输入对齐主要利用不同模态的X-Text配对数据集,通过最小化描述文本的生成损失进行优化。多分支Omni-MLLMs对各模态的投影器分别进行对齐训练,而单分支Omni-MLLMs则采用渐进式策略按特定顺序对齐多模态。此外,部分分支Omni-MLLMs通过预对齐的模态特征空间间接实现其他低资源非语言模态与文本的对齐。
输出对齐训练通常使用与输入对齐相同的X-Text配对数据集,并遵循相同的训练顺序。基于标记的生成方法通过最小化模态特定离散标记的文本生成损失优化扩展的大语言模型头部,而基于表示的生成方法则通过信号标记的生成损失、输出表示与解码器条件向量的L2距离以及条件潜变量去噪损失来优化输出投影器。
4.2多模态指令微调
指令微调阶段旨在提升Omni-MLLMs在任意模态下的泛化能力,主要通过指令跟随数据集计算响应文本的生成损失进行优化。对于具备生成能力的模型,还可能结合输出对齐阶段的损失进行优化。
与特定模态大语言模型相比,Omni-MLLMs不仅利用多种单模态指令数据进行训练,还使用跨模态指令数据增强跨模态能力,部分工作采用多步微调策略,按特定顺序引入单模态和跨模态指令数据以逐步提升能力。
4.3其他训练技巧
·一些Omni-MLLMs直接利用特定模态大语言模型(Specific-MLLMs)训练好的投影器,以减少对齐阶段的训练开销。
·采用PPO和ADPO等人类反馈训练方法,以更好地对齐人类偏好。
·在渐进式对齐预训练或多步指令微调过程中,一些工作将先前训练的模态数据与当前新模态数据混合训练,以避免以学习模态知识的灾难性遗忘。
5.数据构建和测试
5.1对齐训练数据
Omni-MLLMs利用多种模态的文本描述数据集构建X-Text配对数据进行对齐预训练。而对于数据稀缺的模态(如深度图和热力图),部分工作采用DPT模型或图像翻译模型在图像-文本数据基础上合成。此外,部分工作还使用交错数据集进行对齐预训练,以增强上下文理解能力。
5.2指令微调训练数据
大多数工作利用跨模态下游数据集结合预定义模板构建跨模态指令。部分Omni-MLLMs利用标注数据集的标签或预训练模型提取多模态元信息,并使用强大的LLMs生成跨模态指令。另外一些工作通过TTS工具或Text2X模型将单模态指令转换为跨模态指令,例如将图像-文本指令转换为图像-语音-文本指令(Uni-Moe),或将纯文本指令转换为多模态指令(AnyGPT)。
5.3测试基准
·单模态理解:评估Omni-MLLMs对不同非语言模态的理解和推理能力,包括下游X-Text2Text数据集(如X-Caption、X-QA和X-Classification)以及综合多任务基准测试。
·单模态生成:评估Omni-MLLMs生成单一非语言模态的能力,包括Text2X生成任务(如音频生成)和Text-X2Text编辑任务(如语音和视频编辑)。
·跨模态理解:评估Omni-MLLMs对多种非语言模态(如图像-语音-文本、视频-音频-文本以及图像-3D-文本)的联合理解和推理能力。
·跨模态生成:Omni-MLLMs结合其他非语言模态输入生成非语言模态的能力。例如,X-VILA提出的Xs-Text2X基准测试包括图像-文本生成音频和图像-音频-文本生成视频等任务。
6.现有挑战和方向
6.1更多模态的扩展
大多数Omni-MLLMs只能处理2-3种非语言模态,且在扩展更多模态时仍面临一些挑战。
·训练效率:通过额外对齐预训练和指令微调引入新模态会增加训练成本,利用特定模态大语言模型(Specific-MLLMs)的先验知识或预对齐编码器可减少开销,但可能影响跨模态性能。
·灾难性遗忘:扩展新模态可能调整共享参数,导致已训练模态知识的遗忘,混合训练数据或仅微调模态特定参数可部分缓解,但会增加训练复杂性。
·低资源模态:数据合成方法可缓解低资源模态的文本配对数据和指令数据缺乏问题,但缺乏真实模态数据可能导致对该模态的理解偏差。
6.2跨模态能力
·长上下文:当输入包含多个序列模态(如视频、语音)时,多模态标记序列的长度可能超出大语言模型的上下文窗口,导致内存溢出,而标记压缩或采样方法虽能减少输入标记数量,但会降低跨模态性能。
·模态偏差:由于训练数据量不平衡和模态编码器性能差异,Omni-MLLMs在跨模态推理中可能倾向于关注主导模态而忽略其他模态信息,平衡模态数据量或增强特定模态模块可能有助于缓解此问题。
·时序对齐:处理具有时序依赖性的多模态数据时,保留其时间对齐信息对跨模态理解至关重要,部分工作通过交错模态特定标记或插入时间相关特殊标记来保留音视频的时序对齐信息。
·数据与基准测试:尽管Omni-MLLMs采用多种方法生成跨模态指令数据,但在指令多样性、长上下文对话和多模态交互范式方面仍有改进空间,同时跨模态基准测试在任务丰富性和指令多样性方面也落后于单模态基准测试,且覆盖的模态种类有限。
6.3应用场景
Omni-MLLM的出现为多种应用带来了新的机遇和可能性,包括实时多模态交互(如视觉与语音的高效实时交互)、综合规划(利用多模态互补性实现更优的路径和动作规划)以及世界模拟器(不仅理解和生成多模态,还能预测任意模态组合的状态转换)。
7.总结
本文对Omni-MLLM进行了全面的综述,深入探讨了该领域的核心内容。具体而言,我们将Omni-MLLM分解为四个关键组成部分,并根据模态编码和对齐方法对其进行了分类。我们详细总结了Omni-MLLM的训练过程及其使用的相关资源,并归纳了当前面临的挑战和未来发展方向。本文是首个专注于Omni-MLLM的系统性综述,希望为相关领域的进一步研究提供参考和启发。