

思维链技术(Chain-of-Thought, CoT)是一种有效增强大语言模型(Large Language Model, LLM)推理性能的方法。通过要求模型在生成答案的同时提供推理过程,来引导模型更深入地思考问题并探索不同的推理思路,从而增强模型的推理能力。然而由于模型幻觉等原因,即使对于相同的问题,模型生成的结果会很大程度受到输入内容的影响。为了解决这一问题,许多前人工作提出通过优化模型的输入,来充分发挥模型的推理能力。然而,现有的研究主要集中于方法设计,缺乏对输入是如何影响推理稳定性的相关分析,限制了研究者对思维链机理的理解和未来方法的设计。为了解决这一问题,我们首次给出了不同因素对思维链鲁棒性的机理分析。本论文从理论上刻画思维链推理的鲁棒性边界,并据此提出可提升稳定性的提示选择策略。

Technical Report (arXiv): https://arxiv.org/abs/2509.21284
OpenReview (ICLR 2026): https://openreview.net/forum?id=cusZbViSLd
ICLR Poster Page: https://iclr.cc/virtual/2026/poster/10008458
Code (anonymous): https://anonymous.4open.science/r/CoT-Robust-DF71
CoT-Robust 的核心利器:自迭代视角下的鲁棒性边界
我们将CoT看作是多轮自迭代的生成过程,证明了对于任意自迭代函数
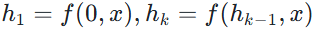
输入扰动对输出波动的影响满足:
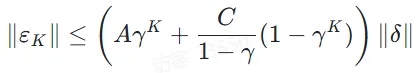
其中K表示思维链步数,δ表示输入扰动,ε表示输出波动,γ, C表示f的利普希茨常数
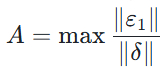
可接受范围 R:在实际使用时,我们不需要完全要求输出波动为零,只需要其在特定的可接受范围R内即可。
稳定模型要求:此外对于一个推理稳定的模型,其在处理输入波动时,应该尽可能降低而非放大波动的影响,即对应的利普希茨常数要小于1。
不可消除的阈值:通过令上式右侧小于R,并令K→∞,我们可以得到:
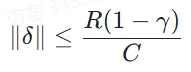
上式表明,即使是无限长的思维链,也无法完全消除输入扰动的影响。
应用到单层自注意力模型:嵌入范数为何关键?
我们将上述结论应用到单层自注意力模型上,其可以看作是简化的Transformer架构。我们证明了当思维链无限长时,单层自注意力模型上的输出波动满足:
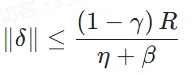
其中η表示残差流系数,γ和β为正相关于嵌入向量范数的系数。上述结果表明,嵌入向量范数越大,会导致不等号右侧的上界变小,导致可接受的输入扰动变小。因此,在固定模型时,我们需要降低嵌入向量的范数,从而增大输入扰动的可接受范围。
实验设置与评价指标
我们在MATH、MMLU-Pro和GPQA三个主流推理数据集和Llama2-7B、Llama-3.1-8B、DeepSeek-R1-Distilled-Llama-8B和Qwen3-8B四个主流的LLMs上进行了实验,并使用扰动输入后输出的归一化熵(OF)作为评价输出波动情况的指标。
实验 1:思维链步数与输出波动
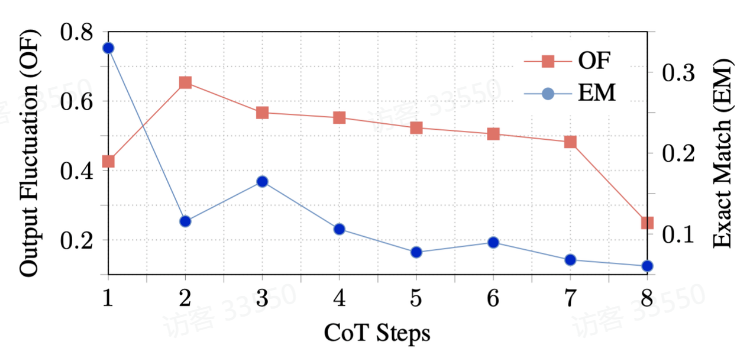
上图表明,随着思维链步数的增加,整体表现出下降的趋势,证明了我们关于思维链步长结论的正确性。而步数为1时OF相对较低,是因为只需要一步回答的问题较为简单,因此模型的输出波动较小。
实验 2:嵌入向量范数与输出波动
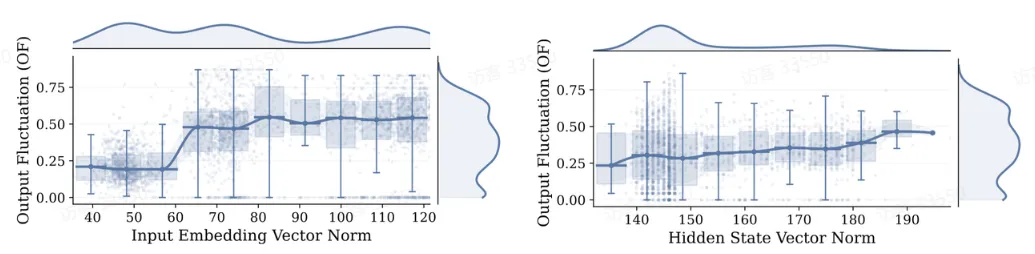
上图表明,嵌入向量范数与输出波动呈负相关,验证了我们关于嵌入向量范数结论的正确性。
输入优化策略:用理论指导提示选择
此外,我们还将我们的方法应用于输入优化方法上,发现通过降低输入嵌入向量的范数,可以显著提升模型的推理稳定性。具体来说,我们首先让模型根据相同问题不同的输入获得多个不同的输出,然后选取(Rx Rh)^2最小的输出作为最终答案。该方法相较于OPRO、CFPO等前人方法,在三个数据集上表现出了一致的性能提升,证明了我们的理论研究确实可以指导实际方法的设计。
总结与展望
本文从理论上刻画了思维链推理的鲁棒性边界,指出推理步数增加能降低扰动影响但存在不可消除的阈值,同时揭示输入与隐藏状态向量范数是鲁棒性下降的关键因素,并据此提出可提升稳定性的提示选择策略。未来研究可沿着“范数可控”的方向把鲁棒性目标融入训练与推理流程,并在更复杂分布转移与对抗扰动场景中验证其对可靠推理与安全部署的长期收益。