

大模型代码能力评估和代码强化学习基于测试用例来提供正确性。然而,人工编写的黄金测试用例稀缺且昂贵,由 LLM 自动生成的测试用例质量又缺乏科学的衡量标准——现有评估方法要么依赖海量错误代码暴力比对,计算成本高昂且分数严重膨胀;要么启发式采样以偏概全,无法覆盖关键的边界情况。为此,我们从“错误代码-测试用例结果”的二元矩阵视角出发、为测试用例质量构造了完善的评价基准。它首次利用矩阵的秩统一回答了「需要多少错误代码」与「需要多少测试用例才能完整覆盖这些错误代码」两大根本问题,并通过 WrongSelect 算法从数十万份竞赛提交中精选出不足 2% 的最具区分度的紧凑的错误代码集,在大幅降低评估成本的同时彻底消除分数膨胀。实验结果表明,即使是当前最先进的测试用例生成方法在 TC-Bench 上也仅能达到约 60% 的排除率,揭示了这一领域巨大的提升空间,为未来研究指明了清晰方向。

https://huggingface.co/datasets/Luoberta/TC-Bench
https://github.com/Luowaterbi/TC-Bench
该论文录用于 ICLR 2026。
评估测试样例质量的困境
当前大模型代码能力评估和代码强化学习的奖励信号完全建立在测试用例之上: 全部通过视为做对,通过比例则可以用于reward分数。然而,收集高质量的测试用例既困难又昂贵,这促使人们使用LLM来自动生成测试用例。这带来了一个新的关键挑战:我们如何严格评估生成的测试用例的质量?现有工作通常计算这些测试用例在收集的大规模错误代码上的排除率,这导致了高昂的计算成本和严重的分数膨胀问题。因为海量错误代码一股脑堆入评估时,大量重复、琐碎的错误代码会淹没少数真正关键的边界错误代码,导致分数严重膨胀——一组只能排除常见错误的基础测试用例,与一组能精准捕获罕见边界缺陷的优秀测试用例,在评分上几乎难以区分。这背后隐藏着两个更根本的问题:究竟需要多少错误代码,才能完整表征一个问题的所有错误模式?又至少需要多少测试用例,才能将这些错误模式都区分开来?
为了回答这两个问题,我们需要一个全新的评估框架——它不仅能扮演「裁判」的角色判定测试用例的好坏,更能担当「诊断师」,从数学上精确刻画错误的多样性与测试的充分性。
WrongSelect:从矩阵视角精选错误代码
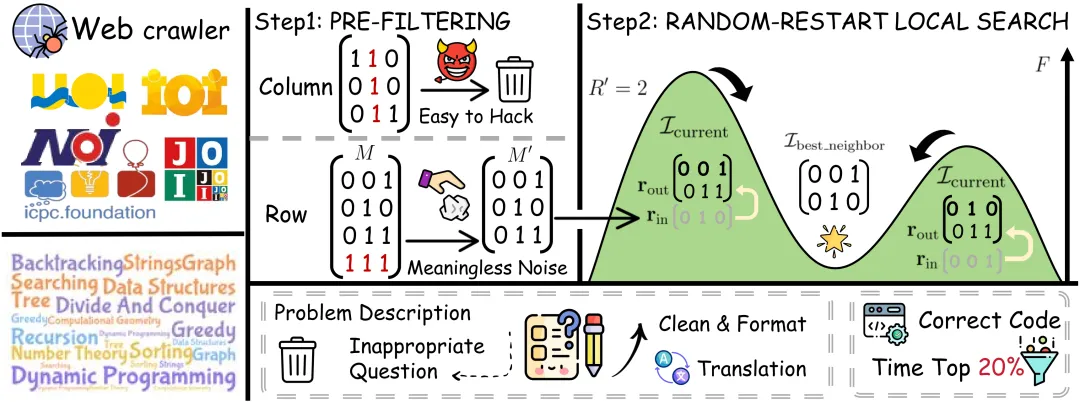
TC-Bench 的核心引擎是 WrongSelect 算法。它的设计思想可以用一句话概括:把「选错误代码」这件事,变成一个严格的线性代数问题。
二元矩阵建模:将错误「可视化」。 对于每道编程题,我们将所有错误代码在各测试用例上的通过/失败结果编码为一个二元矩阵——行代表错误代码,列代表测试用例,通过记 0、失败记 1。每一行就是一段错误代码独有的「故障签名」,刻画了它究竟在哪些测试点上出了问题。这个矩阵的秩同时回答了前述两个根本问题:它既是独立错误模式的数量,也是完全区分这些模式所需的最少测试用例数的上界。
有原则的预过滤:去除噪声与冗余。 原始数据中充斥着大量噪声。在列维度上,我们剔除所有存在「全 1 列」的题目,这些题目往往对应过于简单或错误代码不充分的题目,约占原始数据的 5%。在行维度上,我们过滤掉失败率超过 80% 的错误代码——这类代码通常是只能通过公开测试样例的背景噪声,任何扩展测试用例都能轻松排除它们,约占 13%。最后,我们排除秩低于 5 的矩阵,确保每道题具有足够的多样性。
随机重启局部搜索:逼近最优基。 在过滤后的矩阵上,我们的目标是选出一组行基(即一组错误代码),使其数量恰好等于矩阵秩,同时内部多样性最大化——以平均 Jaccard 相似度衡量,越低越好。这是为了错误代码之间重叠度应该尽量低,能够代码不同的错误模式。对于这个 NP-hard 的组合优化问题。WrongSelect 采用随机重启局部搜索策略:从随机初始基出发,反复尝试将基内成员与基外候选进行交换,若多样性改善则接受,直至收敛至局部最优;随后从新的随机起点重启搜索,最终取全局最优解。实验表明算法收敛迅速,且可高效并行化。
数据构建:从竞赛提交到诊断基准
高质量原始数据采集: TC-Bench 的数据来源于 USACO、IOI、ICPC 等顶级编程竞赛及高质量训练集,初始包含 3,321 道题目和超过 223 万份提交。我们仅保留拥有完整测试用例执行结果的题目,经筛选后得到 1,763 道题、15,457 份正确代码和 554,056 份错误代码。
题目描述标准化: 为确保评测的公平性与一致性,我们对题目描述进行了严格的标准化处理。首先剔除依赖图片、交互式判定或特殊运行环境的题目;然后清洗源码标签、URL、HTML 及非标准数学公式;最后使用 GPT-4o 将非英文题目翻译为英文,并经人工校对确保语义准确。
错误代码精选: 为消除运行环境差异带来的干扰,我们仅保留标记为 Wrong Answer 的 C++ 提交,得到 1,698 道题、282,458 份错误代码。经过 WrongSelect 的预过滤与局部搜索,最终从中精选出 9,347 份核心错误代码——不足原始数量的 2%,却完整覆盖了所有独立错误模式。
正确代码采样: 正确代码的核心差异在于运行时间和内存消耗。过于宽松或严格的正确代码集会影响评测结果的公正性。我们对每道题的正确提交按运行时间归一化后,从前 20% 中随机抽取 8 份,最终得到 7,016 份正确代码。
通过这套严谨的流水线,TC-Bench 最终包含 877 道标准化题目、9,347 份诊断性错误代码和 7,016 份正确代码,构成一个紧凑、多样且抗膨胀的高质量评测基准。
实验
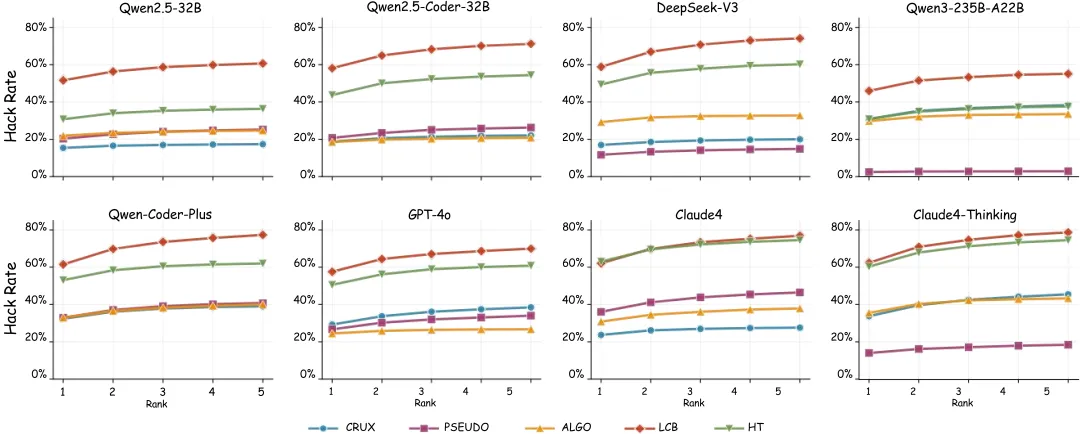
为了验证 TC-Bench 的评测能力与区分度,我们在 TC-Bench 上对 5 种主流测试用例生成方法(CRUX、PSEUDO、ALGO、LCB、HT)和 13 个LLM(涵盖 GPT-4o、Claude-Sonnet-4、Claude4-Thinking、DeepSeek-V3、Qwen-Coder-Plus 等开源与闭源模型)进行了全面评测。评测采用两个核心指标:PassRate(生成的测试用例通过正确代码的比例)和 HackRate(成功排除错误代码的比例)。
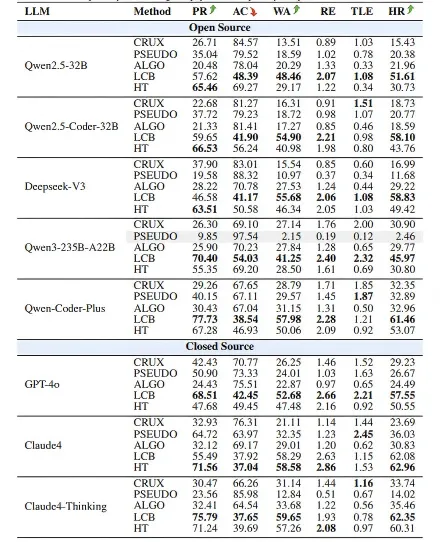
当前最强方法也仅能达到约 63% 的排除率。 实验结果显示,即使是表现最好的组合 Claude Sonnet 4 + HT,其 HackRate 也不足 63%,意味着超过三分之一的错误代码未能被任何生成的测试用例捕获。这一结果有力地证明了 WrongSelect 所精选的错误代码集确实具有高度的区分度与挑战性,现有方法在面对复杂、多样的错误模式时仍存在巨大的提升空间。
高 PassRate 并不意味着高 HackRate。 一个容易被忽视的陷阱是:生成大量「容易通过」的测试用例可以轻松刷高 PassRate,却几乎无法排除真正棘手的错误代码。例如在 Qwen2.5-32B 和 DeepSeek-V3 上,CRUX 的 PassRate 显著高于 ALGO,但其 HackRate 却大幅落后。这表明 PassRate 单独作为指标具有很强的误导性,TC-Bench 的 HackRate 指标才能真实反映测试用例的诊断能力。
方法选择的影响远大于模型规模。 实验结果一致表明,测试用例生成方法的选择对最终性能的影响,远超模型本身的规模或开源/闭源属性。例如,Qwen2.5-Coder-32B 的参数量少于 DeepSeek-V3,但两者在 LCB 方法下的 HackRate 仅相差约 1%;而同一模型上,LCB 与 CRUX 之间的差距可达 40 个百分点。这说明设计更好的测试生成策略,比单纯堆叠模型参数更为关键。
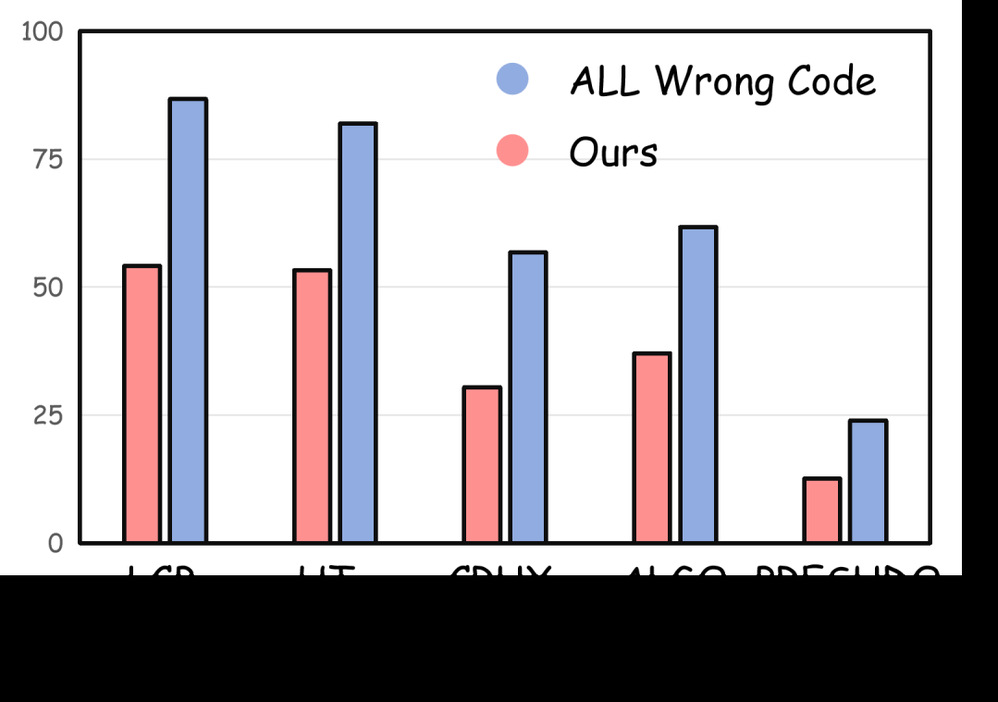
TC-Bench 有效消除分数膨胀。 通过随机抽取 100 道题,对比 Claude Sonnet 4 Thinking 在全量错误代码集与 TC-Bench 上的表现,差距一目了然:在未经筛选的全量集上,LCB 的 HackRate 接近 100%,看起来近乎完美;但在 TC-Bench 上,同一方法仅约 50%。这一巨大落差直观地证明了,未经精选的错误代码集中大量重复、琐碎的错误制造了严重的分数膨胀假象,而 TC-Bench 通过保留最具代表性的错误模式,提供了更加真实、公正的评测。
总结
TC-Bench 通过创新的二元矩阵理论框架、高效的 WrongSelect 精选算法和严谨的数据构建流水线,为测试用例生成评估领域建立了一个全新的范式。它不再简单地堆砌错误代码、比拼排除数量,而是致力于从数学上「理解」错误的多样性、「诊断」测试的充分性,为构建更可靠的代码评估与强化学习体系奠定坚实基础。
目前,TC-Bench 数据集及相关评测代码已全面开源,希望能与社区共同推动测试用例生成技术的发展,让代码评估从「粗放计数」迈向「精准诊断」。