

核心观点:现有稀疏注意力方法多在“序列维度”压缩,容易丢失关键信息。ProxyAttn 另辟蹊径,利用长文本下注意力头表现趋同的特性,在“Head维度”进行压缩。通过一个“代理头(Proxy Head)”来预估重要性,实现了精度与速度的帕累托最优。
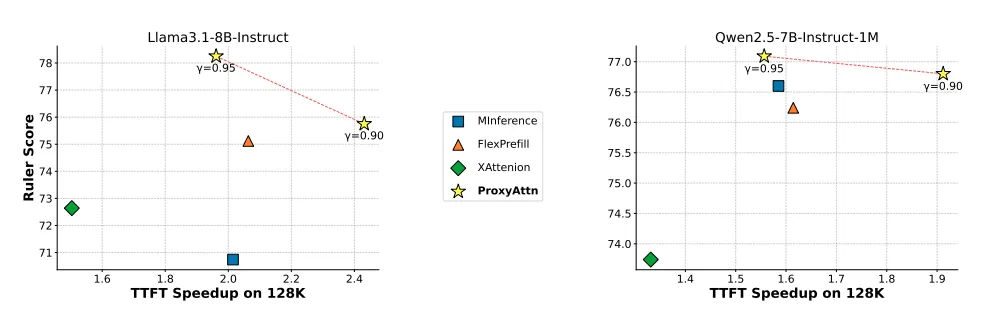
ProxyAttn在多个模型上达到了稀疏注意力方法在性能和效率上的帕累托最优
论文链接:https://arxiv.org/pdf/2509.24745
仓库链接:https://github.com/wyxstriker/ProxyAttn
该论文录用于 ICLR 2026。
1.引言:打破长文本的O(N^2)诅咒
LLM处理长文本的核心瓶颈在于注意力机制的计算复杂度随序列长度呈平方级增长。为了解决这一问题,稀疏注意力应运而生。其核心思想很简单:并非所有的Token都重要,我们只需要计算那些真正相关的Token对即可。
然而,现有的稀疏注意力方法通常通过在序列维度对 Query 和 Key 进行池化压缩来降低估算成本。这种“模糊化”处理虽然快,但往往会遗漏细粒度的关键信息,导致模型在处理精细任务(如大海捞针)时性能下降。
针对这一痛点,我们提出了 ProxyAttn。我们观察到在长文本场景下,不同注意力头的关注点存在惊人的相似性。基于此,我们提出一种无需训练的方法,通过在 Head 维度进行压缩来构建“代理注意力”,搭配块级别的最大池化,在保持全精度Token信息的前提下,实现了近乎无损的块稀疏注意力加速。
2.背景:为什么我们需要“块”稀疏?
稀疏注意力的底层原理
标准的注意力计算公式可以按如下形式表示,其中alpha_ij代表softmax归一化的Qi与Kj内积:
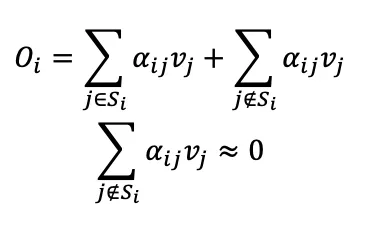
在长文本中,注意力分数矩阵通常是高度稀疏的。绝大多数 QK内积alpha的分数极低,经过Softmax后对最终输出O贡献微乎其微。理论上,跳过这些低分块的计算,不会影模型效果。
为什么必须是 Block-wise?
虽然Token级别的稀疏最精准,但在硬件上难以高效实现。现代GPU加速算子(如 FlashAttention)均基于分块(Tiling)计算。非结构化的稀疏读取会导致严重的显存访问延迟。只有基于 Block 的稀疏(即保留一整块 128*128 的区域或丢弃整块),才能无缝接入 FlashAttention 的加速流水线。
现有方法的局限
为了决定“保留哪一块”,现有的方法通常对 Key 和 Query 的 block 进行池化操作,用压缩后的小向量计算粗略分数。序列维度的压缩会抹平 Token 间的差异。一个包含关键信息的 block 可能因为平均分不高而被错误丢弃。
3.观察:注意力头间表现的异同
ProxyAttn 的灵感来自于我们对长文本下 Attention Head 行为的深入观察。
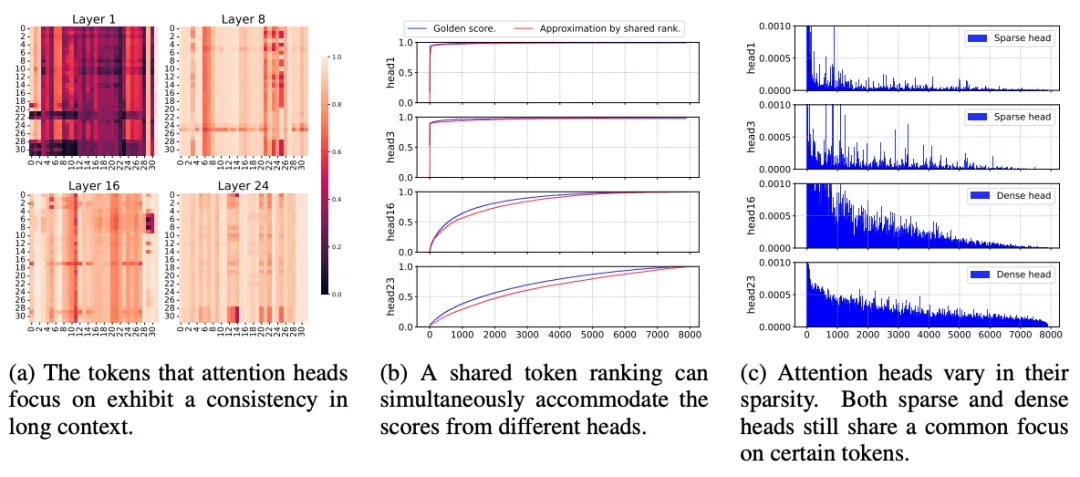
观察实验
相似性:英雄所见略同
在处理长文本时,随着层数加深,不同注意力头关注的内容开始趋同。如图a所示,我们计算了一个 Head 的 Top-K token 在另一个 Head 中的累积注意力分数。结果显示,层数越深,不同 Head 关注的区域重叠度越高(Overlap 接近 1.0)。这与短文本下 Head 各司其职的模式截然不同。如图b所示,既然关注点相似,我们是否可以用一个简单的“代理”来代表所有人?实验表明,通过简单的池化获得的“代理头”,其生成的 Token 排序序列与各个独立 Head 的累积注意力曲线高度一致。
差异性:重点一致,但“视力范围”不同
虽然大家关注的重点区域一样,但对“背景噪音”的过滤程度不同。如图c所示,在同一共享排序下,有的 Head 是“聚焦型”的稀疏头(只看Top 1%),有的是“发散型”的稠密头(看Top 50%+)。不同注意力头的主要差异在于稀疏度,而非关注对象。
启发:
考虑到注意力头间的异同表现,我们不需要为每个 Head 单独估算重要性(太慢),也不需要压缩序列丢失信息(不准)。我们可以利用共享的代理头获取公共排序,再给不同 Head 分配不同的计算预算。这便是ProxyAttn方法的核心动机和设计思路。
4.ProxyAttn方法详解
ProxyAttn 是一个即插即用的免训练框架,主要包含两个核心步骤:基于头池化的重要性估计以及基于动态预算分配的动态掩码构建。
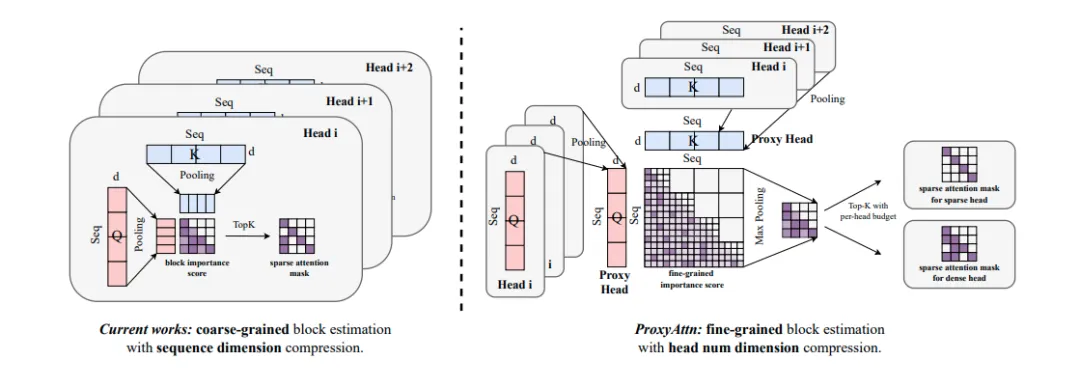
相比先前方法,ProxyAttn的整体框架示意图
步骤一:基于头池化的重要性估计
利用“相似性”观察,我们不再分别计算所有 Head 的 Score,而是构建一个 Proxy Head。整体流程如上图所示:
Head Pooling:将同一层(或同一分组)内的 Q 和 K 在 Head 维度进行聚合。最终得到对应的代理头。
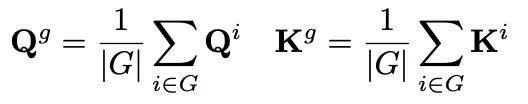
Score Estimation:根据代理头估计出token级别的注意力得分,再通过最大池化得到Block级别的重要性分数来指导后续的稀疏注意力选择。特别地,我们通过将QK内积运算与最大池化运算在Block级别进行了算子融合,实现了更加高效的注意力分数估计。
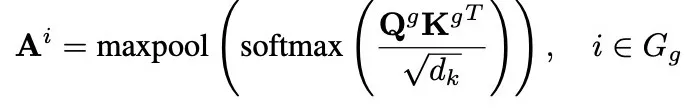
Block Ranking:基于上述得到的注意力得分对KV Block进行重要性排序,再根据后续计算的预算进行TopK的稀疏注意力计算。整个注意力估计过程的计算量从 H*N 降低到了 G*N,极大减少了预估开销。其中H是注意力头数量,G是ProxyAttn的分组数量,N为序列长度。
步骤二:基于动态预算分配的动态掩码构建
利用“差异性”观察,虽然排序共享,但不能“一刀切”地截断。推理阶段,我们利用最后一小部分Q Block对不同head的稀疏度进行了块级别的估计,从而实现共享重要性分数的前提下为每个 Head 分配不同的 Block 预算。后续实验表明,采用动态预算相比固定预算,能在低预算下更好地拟合真实注意力分布,显著降低精度损失。
整体算法如下所示:

最终结合步骤一的排序和步骤二的预算,生成最终的 Block Sparse Mask 输送给 FlashAttention。
5.实验结果
长文任务能力实验
在 RULER和 LongBench等主流长文本评测基准上,ProxyAttn 展现了优越的性能。
精度:在相同稀疏率下,ProxyAttn 的精度显著高于 Minference、FlexPrefill 等基于序列压缩的粗粒度方法。
大海捞针:在关键的检索任务中,ProxyAttn 几乎实现了无损的召回。
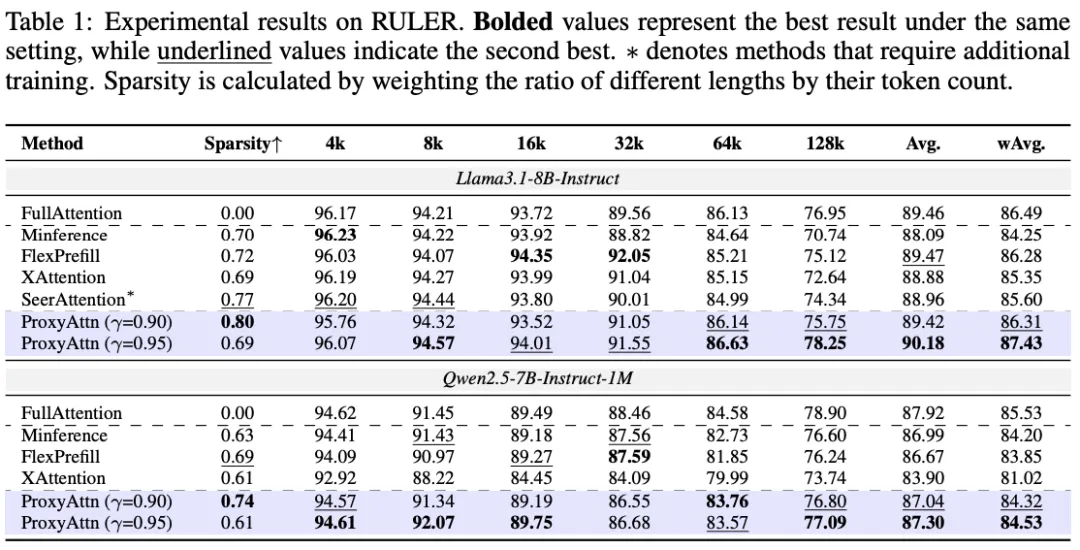
合成数据集RULER上的评测指标
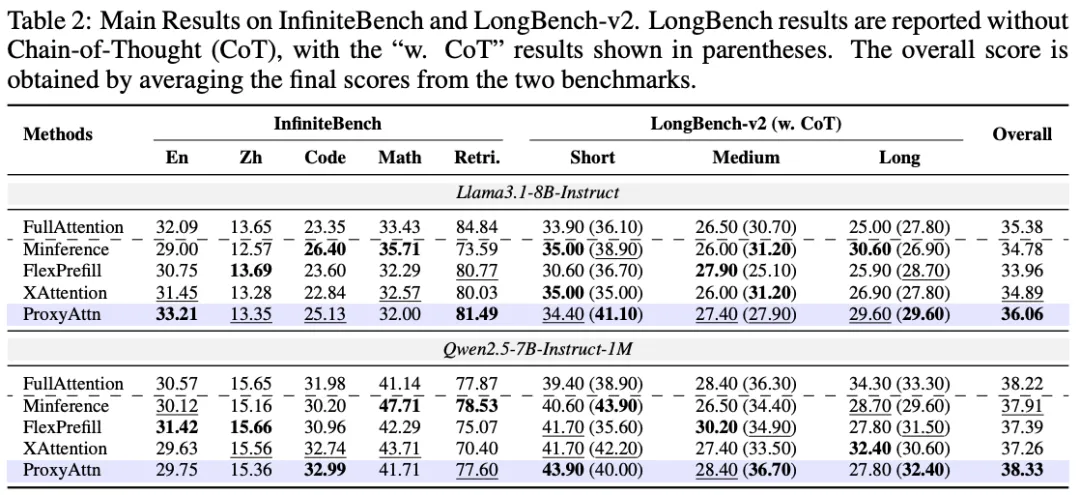
真实数据集LongBench & InfiniteBench上的评测指标
算子加速
得益于无需昂贵的预估计算以及高效的Triton算子支持,ProxyAttn在真实分布的长文数据下展示出显著的加速效果。其中,在Llama3.1-8B模型下相比基线方法FlashAttention最高能达到10.3x的算子级别加速。
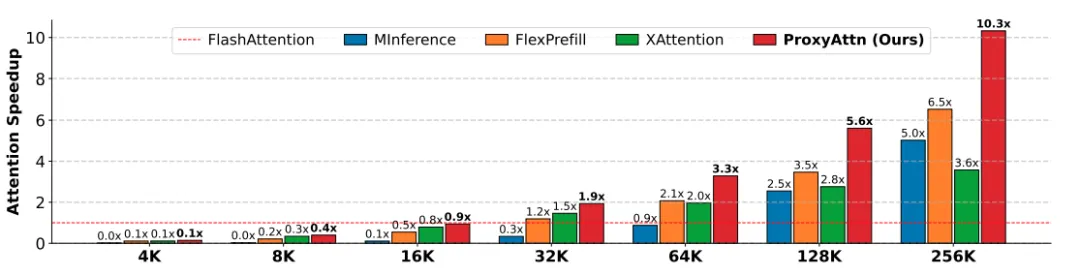
不同输入文本下的算子级别加速效果
此外,尽管获得了更细粒度的Token级别注意力分数,ProxyAttn凭借Head级别池化和Seqlen级别的滑动跳过同样实现了较低的估计成本。如下图所示,哪怕在G=4的设置下,ProxyAttn的估计成本也控制在正常注意力计算的5%以下。
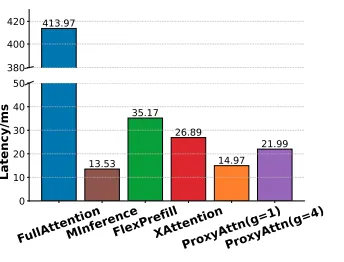
128K输入下不同方法的块重要性估计成本
GQA(分组查询注意力)下的适应性
针对Llama系列和Qwen系列等采用 GQA 的模型,我们发现了有趣的差异:
Llama:头间差异较小,甚至可以将所有 KV Head 压缩为一个 Proxy Head,效果依然稳健。
Qwen:不同 Head 差异性较大。此时,以 GQA 的 Group 为单位(每个 Group 代理一个 Proxy)是最佳策略。不仅精度损失极低,而且这种分组稀疏更兼容张量并行(TP)策略。
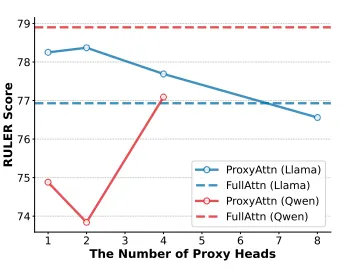
不同Group对ProxyAttn的性能影响
6.总结与展望
ProxyAttn 提出了一种全新的稀疏注意力视角:从压缩序列转向压缩注意力头。
无损:保留了序列维度的完整信息,避免了“大海捞针”时的细节丢失。
高效:通过 Head 维度的聚合,将重要性评估的开销降至最低。
通用:无需训练,即插即用,完美兼容现有注意力的高效实现。
未来,我们将探索 ProxyAttn 在更超长上下文场景以及原生稀疏训练中的潜力。